Alta Disponibilidad y Recuperación de Desastres para servicios PaaS en Azure
Abstract: En el mundo digital de hoy, la continuidad y recuperación de operaciones es vital para negocios en línea, ya que fallos pueden llevar a grandes pérdidas económicas y daño reputacional. A pesar de que Azure es una plataforma líder en la nube, no garantiza por sí sola total disponibilidad o recuperación de datos. Este artículo se centra en estrategias de alta disponibilidad para servicios PaaS en Azure, sugiriendo una estrategia activo-activo y ofreciendo recomendaciones por tipo de servicio. La meta es ayudar a las empresas a fortalecer su arquitectura en Azure y garantizar operaciones sin interrupciones, optimizando la inversión en la nube.
Introducción
A la hora de diseñar y recomendar estrategias de HA y DR, es crucial entender que no hay una solución única que se adapte a todas las necesidades. Las aplicaciones, a pesar de compartir similitudes, tienen características y requisitos únicos que influyen en la elección de la estrategia.
No es lo mismo una funcionalidad en tiempo real que una de procesamiento por lotes. Mientras que la primera necesita garantizar una respuesta inmediata, la segunda puede permitir ciertos retrasos.
En una sola aplicación, puede haber módulos críticos que requieran máxima disponibilidad y consistencia, mientras que otros módulos pueden ser más flexibles en cuanto a estos requisitos.
Y en cuando a datos, mientras algunos necesitan ser accesibles y modificables en tiempo real, otros pueden ser archivados o almacenados con menos frecuencia de acceso.
Aunque es esencial realizar un análisis detallado para una implementación óptima, a continuación, proporcionaremos un conjunto de recomendaciones genéricas que sirven como punto de partida o guía general para HA y DR aprovechando las ventajas de los servicios PaaS en la nube.
Contenido
- Introducción
- Contenido
- Consideraciones sobre Arquitectura Activa-Activa vs Activa-Pasiva
- Determinación de Estrategia para Servicios Individuales
- Conclusiones
Consideraciones sobre Arquitectura Activa-Activa vs Activa-Pasiva
Aunque un diseño que es muy frecuente sobre todo porque en principio se considera económico es el Activo-Pasivo donde la región secundaria se encuentra apagada o corriendo con niveles de capacidad muy bajos, es crucial considerar los beneficios y desafíos que ambas estrategias ofrecen y las ventajas que sobre todo servicios tipo PaaS ofrecen para el modelo Activo-Activo.

Resiliencia Mejorada
En un diseño activo-activo, ambas regiones están operativas, lo que permite que, en caso de fallo en una región, la otra pueda asumir inmediatamente la carga sin demoras significativas. Esto puede resultar en un tiempo de recuperación más rápido en comparación con un escenario activo-pasivo, donde la región pasiva podría requerir tiempo para “despertar” y asumir la carga.
Consistencia de Performance
Con Azure App Services, escalar (scale-up) una instancia desde niveles inferiores a niveles superiores puede causar que la aplicación se reinicie. Esto, combinado con la potencial pérdida de registros de IP, puede resultar en interrupciones no deseadas. En un escenario de desastre, donde una gran cantidad de clientes podría estar tratando de acceder al servicio en la región secundaria, estos reinicios y cambios pueden resultar en una experiencia de usuario subóptima.
Distribución Balanceada de Tráfico
En un entorno activo-activo, es posible distribuir el tráfico entre las dos regiones en función de criterios como latencia o carga. Esto no solo permite aprovechar los recursos en ambas regiones de manera eficiente, sino que también puede ofrecer una experiencia de usuario optimizada al dirigir a los usuarios al centro de datos más cercano o con mejor respuesta.
Sincronización y Consistencia de Datos
Si bien hay desafíos asociados con la sincronización de datos en tiempo real entre regiones en un escenario activo-activo, también se ofrece la ventaja de tener datos disponibles y actualizados en ambas regiones constantemente. Esto puede ser crítico para aplicaciones donde la integridad y actualidad de los datos es vital.
Determinación de Estrategia para Servicios Individuales
La perspectiva de optar por una arquitectura activo-activo, como se describió anteriormente, influenciará las recomendaciones y estrategias que proponemos para cada uno de los servicios individuales que se abordarán a continuación y que son comunes en muchas soluciones de nube. Es fundamental entender que esta recomendación es una propuesta general, basada en la mayoría de los escenarios y características observadas.
Es importante hacer hincapié en que cada servicio y componente de la solución puede tener sus propias peculiaridades y requerimientos. Aunque una estrategia activo-activo puede ser óptima en una visión global, existen situaciones o componentes específicos donde otra estrategia podría ser más adecuada.
Estrategia para Azure App Service Plan
Para garantizar la alta disponibilidad y la resiliencia de los App Service Plan en un escenario de multirregión, proponemos la siguiente estrategia.

Azure Front Door como Balanceador Global
Se recomienda el uso de Azure Front Door para administrar el tráfico entre regiones. Además de ser un balanceador global de carga, Front Door ofrece la ventaja de actuar como un punto centralizado para implementar un firewall de aplicaciones web (WAF), potenciando la seguridad de la aplicación. Esta herramienta permite una configuración flexible en términos de balanceo, ya sea en un esquema de round-robin, en proporciones específicas (lo cual puede ser útil durante despliegues de prueba) o en un modo de failover puro en caso de que una región esté indisponible.
Distribución Equitativa de Capacidad
Idealmente, la capacidad de los App Service Plan debería ser distribuida equitativamente entre las dos regiones activas. Esto no solo asegura una distribución uniforme del tráfico en condiciones normales, sino que también proporciona redundancia en caso de fallos. También tiene que ver con mantener controlado el costo del servicio: Si inicialmente se contemplaba una capacidad K para la región principal, esa capacidad puede ser dividida y ubicarse K/2 en la región principal y otro K/2 en la región secundaria. No obstante, dado que la región principal se encargará de la mayoría de las operaciones de escritura, uno podría considerar una distribución de 2/3 de K en la principal y 1/3 de K en la secundaria. Pero mucha atención: ésta capacidad no debe ser variada en términos de tamaño de las instancias (por ejemplo dejar una P3 en la región principal y una S1 en la secundaria), sino en cantidad de instancias. Por ejemplo, si la solución requiere 3 instancias P3, podemos dejar dos P3 en la región principal y la otra en la secundaria. Si fueran requeridas solo dos P3, podemos hacer una equivalencia de 2 * P3 = 4 * P2 y entonces ubicar tres instancias P2 en la región principal y una o dos instancias P2 en la secundaria. Obsérvese que en ambos casos el tamaño de las instancias es el mismo en ambas regiones. Lo que cambia es la cantidad de instancias.
Respuesta ante Desastres y Escalabilidad
En la eventualidad de un desastre que haga que una de las regiones quede inactiva, es vital que la región activa restante pueda manejar el aumento repentino de la carga. En este escenario, se propone que la región activa experimente un proceso de “scale-out”, es decir, añadir más instancias a la aplicación, para duplicar su capacidad (de K/2 a K). Es crucial enfatizar que este enfoque de “scale-out” es generalmente más rápido y menos arriesgado que un “scale-up” (aumentar las capacidades de una única instancia) que se podría considerar en un enfoque activo-pasivo. La razón detrás de esto es que el scale-up podría involucrar reinicios o cambios que podrían impactar la disponibilidad o el estado del servicio, especialmente cuando se necesita hacer rápidamente en una situación de emergencia.
Por ejemplo, si tenemos una aplicación que requiere cuatro instancias P2 para soportar toda la carga de la solución, y hemos puesto tres instancias P2 en la región principal y una en la secundaria, si llegase a haber un failover, lo que haríamos sencillamente sería agregar tres instancias más de P2 en la secundaria, para satisfacer el requerimiento de las cuatro P2 necesarias para soportar toda la carga: de hecho, dado que un failover es un proceso complejo que puede sobrecargar un poco la infraestructura al principio (entre otras cosas dado que una gran carga de sesiones que estaban en la otra región ahora deberá ser atendida por la nueva), podríamos mejor desplegar en total cinco instancias P2 en la secundaria, mientras se estabiliza el failover y luego volver a bajar a cuatro. Como se mencionó antes, estas operaciones son muy sencillas y no afectan la disponibilidad del servicio. (Las cantidades usadas son solo ejemplo que deben ser validados con las pruebas de carga pertinentes y son solo usadas para ilustrar el concepto).
A cotinuación un diagrama que nos muestra un ejemplo de la resdistribución de capacidad de cómputo en dos regiones orquestadas por Front Door.
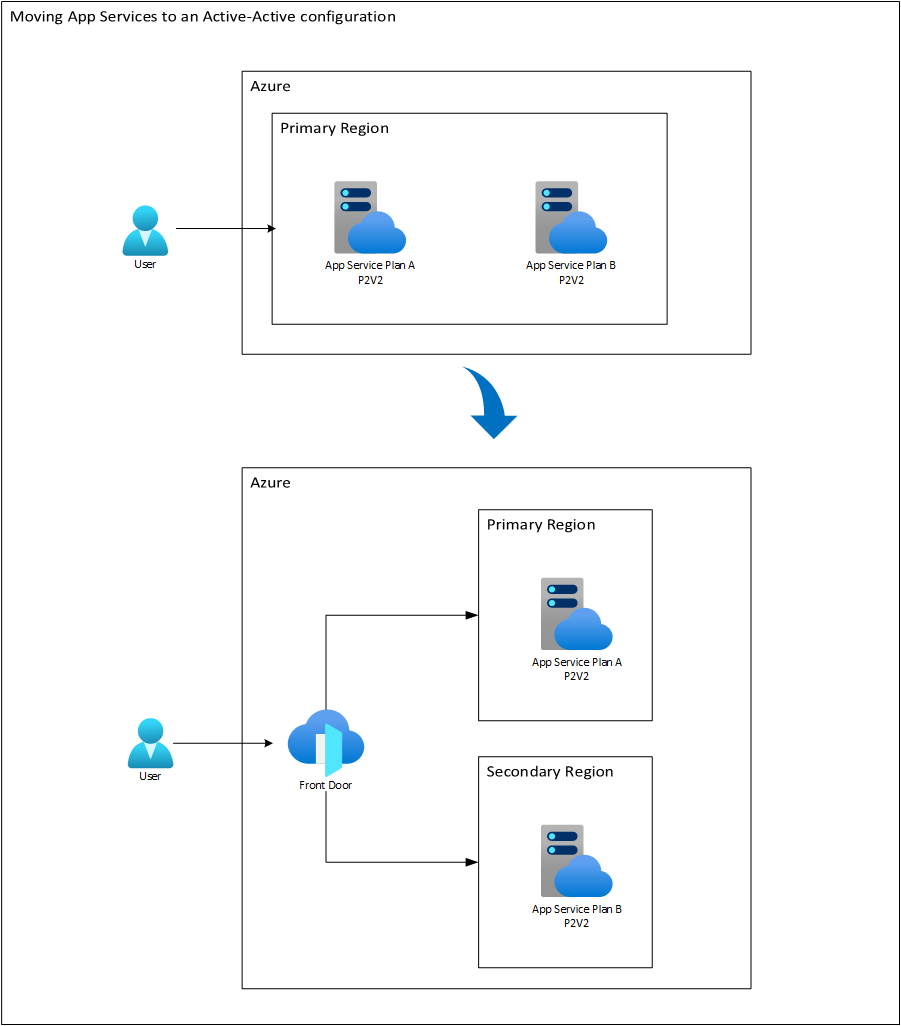
Tengamos en cuenta que aunque los App Service Plan se llaman diferente, las aplicaciones que contienen son las mismas. Solo que de acuerdo a la ruta pedida, Front Door se encarga de hacer el request a uno u otro App Service Plan. De esta manera, cada App Service Plan terminará ejecutando tareas distintas. El principal hará tareas sobre todo de escritura en la base de datos mientras el secundario se encargará de tareas de solo lectura. Esto podría implicar por ejemplo que en un determinado momento requiramos más instancias en la región primaria que en la secundaria. Pero recordemos que siempre sería más conveniente para tener ambientes más predictivos tener las instancias del mismo tamaño. Así que como recomendación está solo variar la cantidad (Scale Out) en vez del tamaño (Scale Up) para los App Service Plan en este caso.
Estrategia para Azure SQL Database
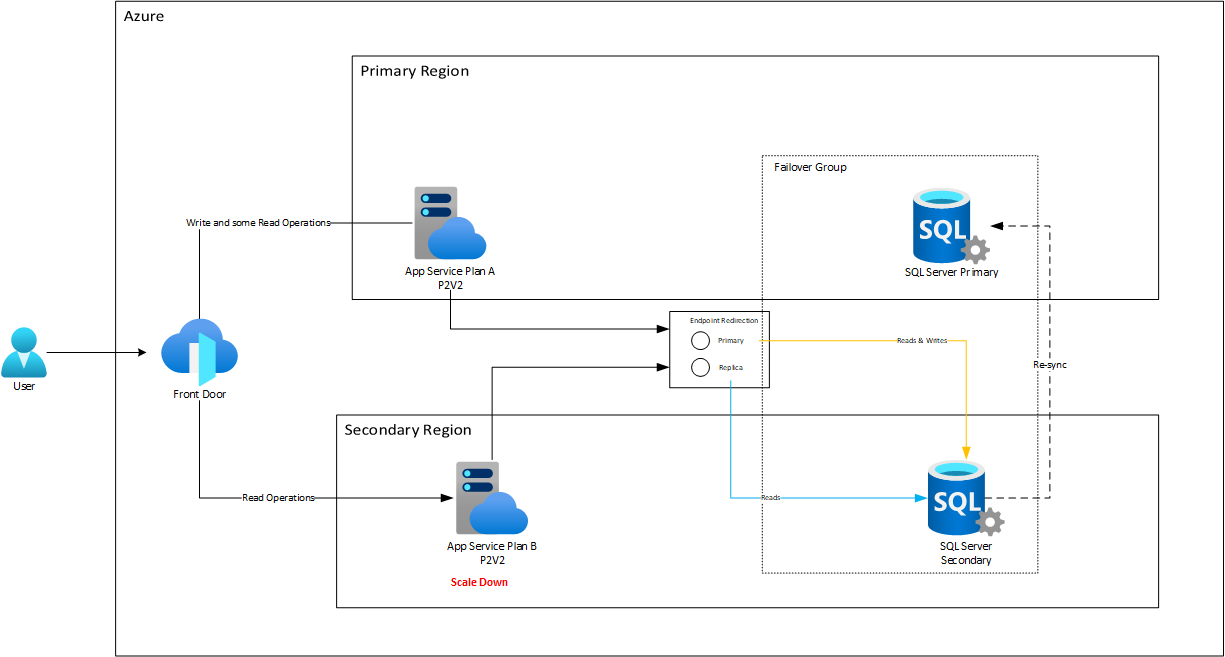
Una de las características más resaltantes de SQL Azure en la gestión de alta disponibilidad es el uso de los Failover Groups. Estos grupos no solo ofrecen recuperación automática y sincronización de datos entre bases de datos primarias y secundarias, sino que además poseen una función conocida como “Endpoint Redirection”.

“Endpoint Redirection” es una ventaja intrínseca de los Failover Groups que nos permite tener una dirección única hacia la cual se canalizan las solicitudes de escritura (en la región principal) y otra para las de lectura (en la secundaria). Es decir, a pesar de tener múltiples regiones y puntos de acceso, todas las operaciones que requieran modificar datos se redireccionan a un punto específico. Esta cohesión garantiza la integridad de la información, evitando posibles conflictos y desincronizaciones.
Al combinar esta capacidad con Azure Front Door, podemos potenciar aún más esta característica. Front Door, gracias a sus capacidades avanzadas de gestión de tráfico, puede ser configurado para dirigir todas las solicitudes de escritura a los backend desplegados en la región principal del Failover Group. De esta manera, cada solicitud de escritura que ingresa a través de Front Door es redirigida no solo al App Service (o cualquier otro servicio de cómputo de backend) correcto, sino que este, a su vez, apunta al endpoint designado del Failover Group en la región primaria. Esto crea un flujo de trabajo optimizado y eficiente para todas las operaciones que involucran cambios en los datos.
Por otro lado, para operaciones que no involucren escritura, como consultas de lectura, Azure Front Door puede gestionar un balanceo ponderado. Esto significa que una porción menor de estas solicitudes puede ser dirigida a la región principal, mientras que una proporción mayor se envía a la región secundaria. Este enfoque no solo distribuye la carga y minimiza la latencia, sino que también aprovecha la infraestructura disponible en ambas regiones, maximizando la eficiencia y la disponibilidad.
Teniendo en cuenta lo anterior, junto con la arquitectura Activo - Activo de App Service, podríamos concretar un modelo conjunto con SQL Azure Database:
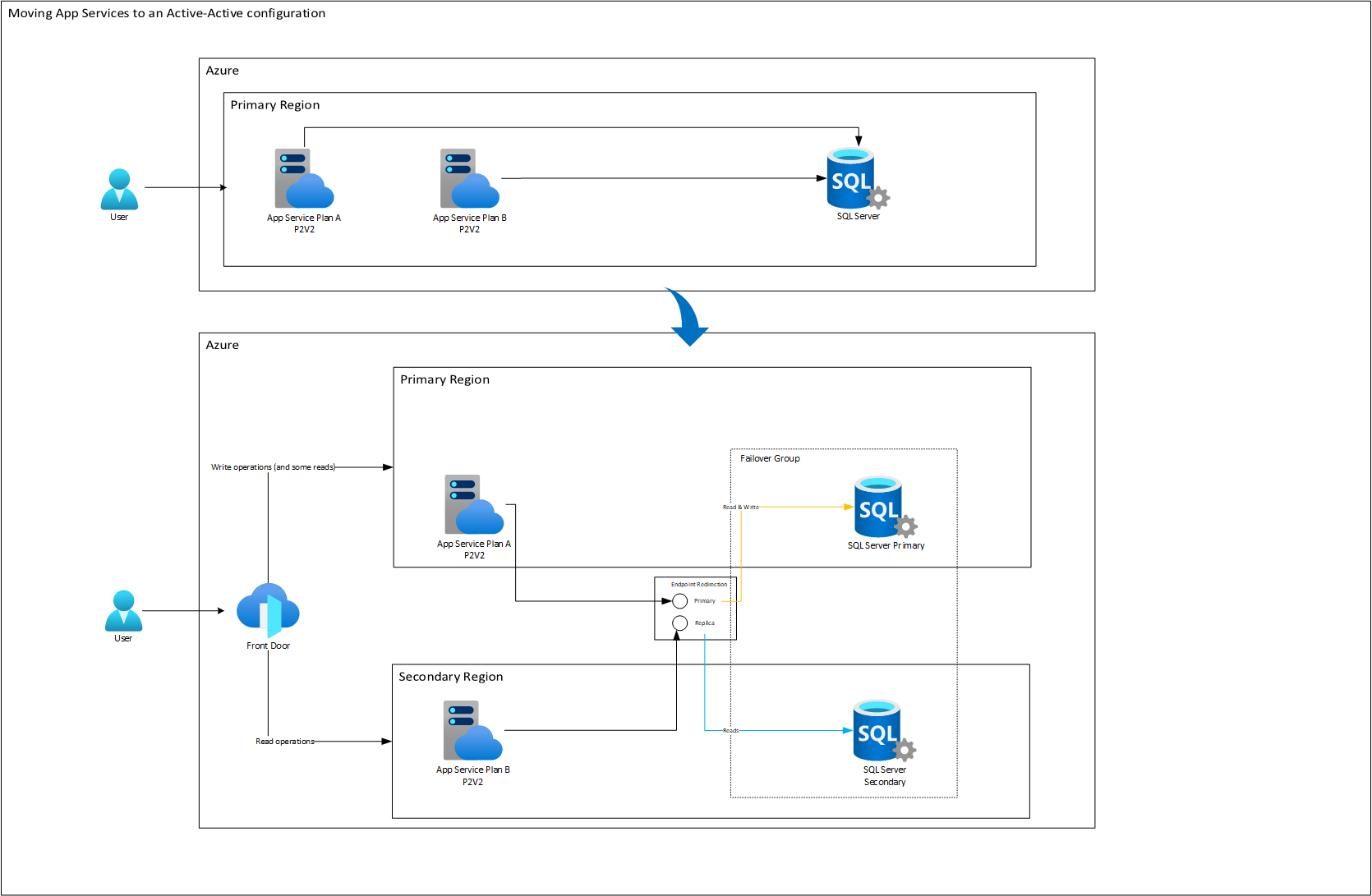
Aquí se mantienen los costos de cómputo idénticos, pero a SQL Database sí hay que crearle una réplica que básicamente duplica sus costos. Pero, en caso de un desastre, el sistema respondería con unos niveles de RTO y RPO muy superiores a los obtenibles en una estrategia pasiva. Observemos en especial como la característica de Endpoint Redirection se encarga de redireccionar automáticamente el tráfico al nodo réplica una vez queda listo después del failover.
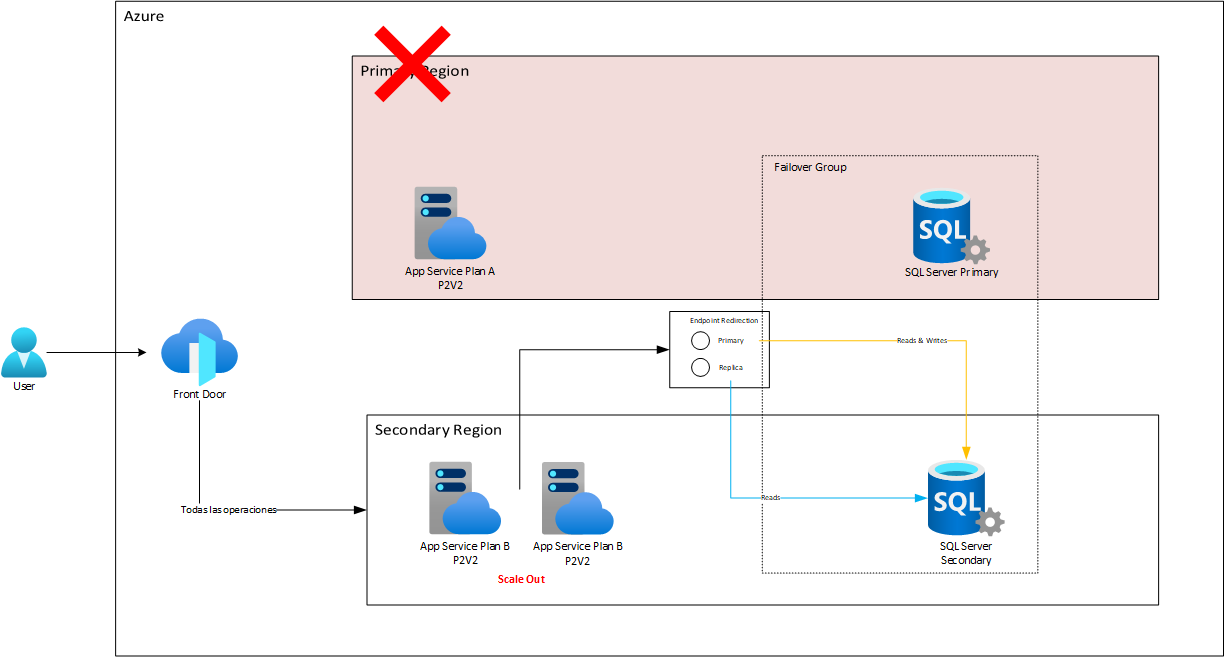
Luego de esto, para el failback, va a pasar algún tiempo mientras la replicación desde la réplica al nodo principal fluye para sincronizar la data que se trabajó durante la falla. Mientras tanto el App Service seguirá trabajando con el nodo secundario. Cuando el failback de Azure SQL Database se completa, entonces Endpoint Redirection reconfigura el tráfico a su estad original:
Estrategia para Azure Storage
Azure Storage es fundamental en cualquier solución basada en la nube, ofreciendo un almacenamiento robusto y altamente escalable. Para decidir una estrategia de alta disponibilidad y recuperación de desastres, es esencial entender las diferencias entre la replicación geográfica automática y manual.

Replicación Geográfica Automática
La replicación automática se destaca por ser fácil de configurar, con menos esfuerzo de programación. Asegura que la data esté respaldada en una región secundaria, aunque de forma asíncrona. Además, solo se permite la escritura en la región primaria, lo que puede simplificar algunas operaciones y evitar conflictos de concurrencia.
Sin embargo, esta simplicidad viene con sus desafíos. La asincronía puede resultar en la pérdida de datos recientes en caso de un failover. Además, durante eventos de failover y failback, la cuenta de almacenamiento no está disponible para escrituras, lo que puede causar interrupciones en las operaciones de la aplicación. Este proceso también requiere copiar toda la data desde la región secundaria de nuevo a la primaria, y viceversa, después de la recuperación. Así, la aplicación necesita ser capaz de operar en modo solo lectura durante estos tiempos. Las lecturas en la región secundaria también pueden estar desactualizadas debido al lag en la replicación.
Replicación Geográfica Manual
El método manual brinda un control más directo y una mayor consistencia de datos, permitiendo escrituras en cualquier región siempre que las condiciones de concurrencia estén adecuadamente manejadas. Las interrupciones por indisponibilidad de escritura son mínimas, y siempre se puede acceder a datos actualizados desde cualquier región. Además, no es necesario copiar toda la data durante el failback, lo que ahorra tiempo y recursos.
Por otro lado, el control adicional viene con una complejidad añadida. Requiere un mecanismo personalizado para replicar y detectar cambios, lo que implica un mayor esfuerzo de desarrollo. También puede haber una latencia adicional en las operaciones mientras se confirman los cambios en ambas cuentas de almacenamiento.
En resumen, dependiendo de las funcionalidades y necesidades específicas relacionadas con el almacenamiento, se puede optar por una estrategia u otra.
Estrategia para Azure Cosmos DB
Azure Cosmos DB es una oferta única dentro de la gama de soluciones de base de datos proporcionadas por Azure. Es una base de datos diseñada con una naturaleza intrínsecamente distribuida, lo que la hace ideal para adaptarse a escenarios de alta disponibilidad y recuperación de desastres.

Cosmos DB sobresale especialmente cuando hablamos de la metodología activo-activo que hemos propuesto para esta solución. A diferencia de otras bases de datos, Cosmos DB permite operaciones como la escritura multimaestro, que posibilita la escritura simultánea en múltiples regiones sin enfrentar conflictos. Esto no solo aumenta la disponibilidad y resistencia de la aplicación, sino que también mejora la latencia al permitir que las operaciones de escritura se realicen en la región más cercana al usuario.
Sin embargo, un aspecto crucial a considerar con Cosmos DB es su modelo de consistencia. Aunque la escritura multimaestro es una ventaja significativa, la elección del nivel de consistencia determina cómo se replican y leen los datos en las diferentes regiones.
Por ejemplo, al optar por un nivel de consistencia “Strong”, garantizamos que los datos estarán actualizados y serán consistentes en todas las regiones. Esta es una opción ideal para aquellas partes de la aplicación que requieren precisión absoluta en los datos. Sin embargo, esta consistencia tiene un coste en términos de latencia y rendimiento.
Por otro lado, hay niveles de consistencia más bajos, que ofrecen una latencia reducida al no esperar la replicación completa de datos antes de completar una operación de escritura o actualización. Estas opciones pueden ser adecuadas para partes de la aplicación donde la velocidad es esencial y se puede tolerar un ligero retraso en la propagación de datos entre regiones. Sin embargo, con niveles más bajos de consistencia, existe un riesgo, aunque pequeño, de pérdida de datos en caso de fallos regionales.
Estrategia para Azure Cache for Redis
La eficiencia y la resiliencia de una solución en la nube están intrínsecamente ligadas a la gestión adecuada de la caché. Al hablar de Azure Cache for Redis, encontramos diversas estrategias de geo replicación, que permiten que su aplicación sea resiliente y esté disponible en distintas regiones geográficas.

Replicación Activa-Pasiva
Azure Cache for Redis ofrece principalmente dos modalidades de geo replicación. La primera, denominada Activa-Pasiva, disponible en el nivel Premium, permite que su instancia de Redis en la región principal se replique de forma automática hacia una región secundaria; en condiciones normales el caché puede ser leído allí pero no escrito y esto nos da cierta escalabilidad que libera al caché principal de excesivas lecturas. Sin embargo, es importante mencionar que, en esta región durante ciertos procesos de sincronización, podrían surgir errores de lectura por lo que es necesario que el código que la acceda esté preparado para regresar a consultar a la región principal si llegan a presentarse estos errores.
En términos de recuperación de desastres, esta modalidad garantiza que, ante fallos regionales, la aplicación pueda seguir accediendo a la data en la región secundaria en bien se complete el failover.
Replicación Activa-Activa
Por otro lado, está la modalidad Activa-Activa, que es parte del nivel Enterprise. Esta permite la replicación activa en hasta cinco regiones de manera simultánea, dándole la capacidad de realizar operaciones de lectura y escritura en todas esas regiones. Es una opción más resiliente y flexible, pero lleva consigo un mayor coste debido a las licencias de Redis y puede presentar complejidades en la gestión de posibles conflictos de datos.
Cachés independientes en cada región
Un punto crucial para considerar es el tipo de contenido que planea cachear. Si se trata de contenido principalmente estático o que cambia esporádicamente, quizás no necesite invertir en geo replicación. Esto, dado que los datos estáticos ofrecen una predictibilidad; sabe exactamente cuándo necesitará realizar cambios y puede planificar estas actualizaciones para momentos que causen la menor interrupción. Además, al evitar la replicación automática para datos que raramente cambian, reduce costos innecesarios y simplifica la infraestructura al no tener que lidiar con posibles conflictos de replicación.
En casos como estos, podemos adicionar este hecho con la arquitectura activa-activa que hemos estado discutiendo para el backend, ya que hay beneficios evidentes en gestionar el caché de forma independiente y permanente en cada región. Una de las grandes ventajas es la latencia reducida. Al permitir que cada backend interactúe con su caché local, las operaciones son notablemente más rápidas, especialmente beneficioso para cargas de trabajo con muchas lecturas. Además, esta independencia garantiza que un fallo en un caché de una región no se propague, aislando así los posibles problemas. Cada caché puede ser personalizado para satisfacer las necesidades específicas de su región, ofreciendo una optimización de costos y eliminando el retraso introducido por la replicación. Ésta es una solución muy similar a la propuesta con la replicación geográfica manual del storage con una facilidad mayor dada por que la información en caché puede ser reconstruida dada su naturaleza efímera.
Estrategia para Azure Event Grid
Una de las características más prominentes de Azure Event Grid es su capacidad de geo replicación automática. Pero es crucial comprender que esta geo replicación se centra en replicar únicamente la definición del servicio y no la data (eventos) en sí.

Cuando se presenta un problema en una región y esta deja de estar operativa, los nuevos eventos son redirigidos y procesados por la nueva región que ha tomado el control gracias a la geo replicación de la definición del servicio. Sin embargo, es vital tener en cuenta que los eventos que ya estaban en la región original antes del problema permanecerán allí, en estado de bloqueo, hasta que la región original se restablezca. Una vez que la región original vuelve a estar operativa, esos eventos son finalmente despachados.
Un punto de atención es el tiempo de vida (TTL) de estos eventos. Si la interrupción en la región original se extiende más allá del TTL de los eventos, existe un riesgo real de que esos eventos se pierdan. Para mitigar este riesgo, es posible configurar la cola de “dead-letter”, que actúa como un respaldo para esos eventos que no se pudieron procesar a tiempo.
Si quisiésemos tener un control más granular sobre la alta disponibilidad y recuperación de desastres, se recomienda implementar una estrategia manual de autorecuperación. Aunque esta estrategia ofrece un mayor control, también requiere de programación adicional del lado del cliente. Por ejemplo, para determinar en qué región operará el Event Grid secundario, será necesario programar la lógica de failover entre dos instancias interregionales de Event Grid. No obstante, es esencial entender que, a pesar de esta intervención manual, aún persiste el desafío de manejar eventos ya enviados y aún no procesados.
Conclusiones
Al diseñar una estrategia de alta disponibilidad y recuperación de desastres para servicios PaaS en Azure, es importante considerar las características y requisitos únicos de cada aplicación. Si bien una estrategia activo-pasivo es comúnmente utilizada, en este caso específico se recomienda una estrategia activo-activo debido a las ventajas que ofrece en términos de resiliencia. No obstante, cada caso puede tener sus características especiales que hagan que se tome un acercamiento distinto: ante cualquier duda podemos comunicarnos y colaborar.