High Availability and Disaster Recovery for PaaS services on Azure
Abstract: In today’s digital world, business continuity and operation recovery is vital for online businesses, as failures can lead to significant financial losses and reputational damage. Although Azure is a leading cloud platform, it does not guarantee total availability or data recovery by itself. This article focuses on high availability strategies for PaaS services on Azure, suggesting an active-active strategy and offering recommendations by type of service. The goal is to help companies strengthen their architecture in Azure and ensure uninterrupted operations, optimizing cloud investment.
Introduction
When designing and recommending HA and DR strategies, it is crucial to understand that there is no one-size-fits-all solution. Applications, despite sharing similarities, have unique features and requirements that influence the choice of strategy.
Real-time functionality is not the same as batch processing. While the former needs to ensure an immediate response, the latter can allow certain delays.
Within a single application, there can be critical modules that require maximum availability and consistency, while other modules can be more flexible in terms of these requirements.
And regarding data, while some need to be accessible and modifiable in real time, others can be archived or stored with less frequent access.
Although a detailed analysis is essential for optimal implementation, below, we will provide a set of generic recommendations that serve as a starting point or general guide for HA and DR leveraging the advantages of PaaS services in the cloud.
Content
- Introduction
- Content
- Considerations on Active-Active vs Active-Passive Architecture
- Strategy Determination for Individual Services
- Conclusion
Considerations on Active-Active vs Active-Passive Architecture
Although an Active-Passive design is frequent mainly because it is initially considered economical, where the secondary region is turned off or running at very low capacity levels, it’s crucial to consider the benefits and challenges both strategies offer, especially the advantages that PaaS services offer for the Active-Active model.
Enhanced Resilience
In an active-active design, both regions are operational, allowing, in the event of a failure in one region, the other to immediately assume the load without significant delays. This can result in a quicker recovery time compared to an active-passive scenario, where the passive region might require time to “wake up” and take on the load.
Performance Consistency
With Azure App Services, scaling up an instance from lower to higher levels can cause the application to restart. This, combined with the potential loss of IP records, can result in unwanted interruptions. In a disaster scenario, where a large number of customers could be trying to access the service in the secondary region, these restarts and changes can result in a suboptimal user experience.
Balanced Traffic Distribution
In an active-active environment, it’s possible to distribute traffic between the two regions based on criteria such as latency or load. This not only allows for efficiently utilizing resources in both regions but also can offer an optimized user experience by directing users to the closest or best-performing data center.
Data Synchronization and Consistency
While there are challenges associated with real-time data synchronization between regions in an active-active scenario, it also offers the advantage of having data available and updated in both regions constantly. This can be critical for applications where data integrity and timeliness are vital.
Strategy Determination for Individual Services
The perspective of opting for an active-active architecture, as described earlier, will influence the recommendations and strategies we propose for each of the individual services addressed below, common in many cloud solutions. It is essential to understand that this recommendation is a general proposal, based on most observed scenarios and features.
It is important to emphasize that each service and solution component can have its own peculiarities and requirements. Although an active-active strategy may be optimal in a global view, there are specific situations or components where another strategy could be more suitable.
Strategy for Azure App Service Plan
To ensure high availability and resilience of the App Service Plans in a multi-region scenario, we propose the following strategy.

Azure Front Door as Global Load Balancer
The use of Azure Front Door to manage traffic between regions is recommended. In addition to being a global load balancer, Front Door offers the advantage of acting as a centralized point to implement a web application firewall (WAF), enhancing the application’s security. This tool allows for flexible configuration in terms of balancing, either in a round-robin scheme, in specific proportions (which can be useful during test deployments), or in pure failover mode if a region is unavailable.
Equitable Capacity Distribution
Ideally, the capacity of the App Service Plans should be distributed equitably between the two active regions. This not only ensures a uniform distribution of traffic under normal conditions but also provides redundancy in case of failures. This also involves controlling the service cost: If initially, a K capacity was contemplated for the main region, that capacity can be divided and located K/2 in the main region and another K/2 in the secondary region. However, since the main region will handle most of the write operations, one might consider a distribution of 2/3 of K in the primary and 1/3 of K in the secondary. But pay close attention: this capacity should not vary in terms of the size of the instances (for example, leaving a P3 in the primary region and an S1 in the secondary), but in the number of instances. For instance, if the solution requires 3 P3 instances, we can leave two P3s in the primary region and the other in the secondary. If only two P3s were required, we can make an equivalence of 2 * P3 = 4 * P2 and then place three P2 instances in the primary region and one or two P2 instances in the secondary. Notice that in both cases, the size of the instances is the same in both regions. What changes is the number of instances.
Disaster Response and Scalability
In the event of a disaster that makes one of the regions inactive, it is vital that the remaining active region can handle the sudden increase in load. In this scenario, it is proposed that the active region undergo a “scale-out” process, that is, adding more instances to the application, to double its capacity (from K/2 to K). It is crucial to emphasize that this “scale-out” approach is generally faster and less risky than a “scale-up” (increasing the capabilities of a single instance) that could be considered in an active-passive approach. The reason behind this is that the scale-up could involve restarts or changes that could impact the availability or state of the service, especially when needed to be done quickly in an emergency situation.
For example, if we have an application that requires four P2 instances to support the entire load of the solution, and we have placed three P2 instances in the primary region and one in the secondary, if there were to be a failover, what we would simply do is add three more P2 instances in the secondary, to meet the requirement of the four P2s necessary to support the entire load: in fact, given that a failover is a complex process that can overload the infrastructure a bit at the beginning (among other things because a large load of sessions that were in the other region now must be attended by the new one), we might better deploy a total of five P2 instances in the secondary, while the failover stabilizes and then drop back to four. As mentioned before, these operations are very straightforward and do not affect the service availability. (The quantities used are only examples that must be validated with the pertinent load tests and are only used to illustrate the concept).
Below is a diagram that shows us an example of the redistribution of computing capacity in two regions orchestrated by Front Door.
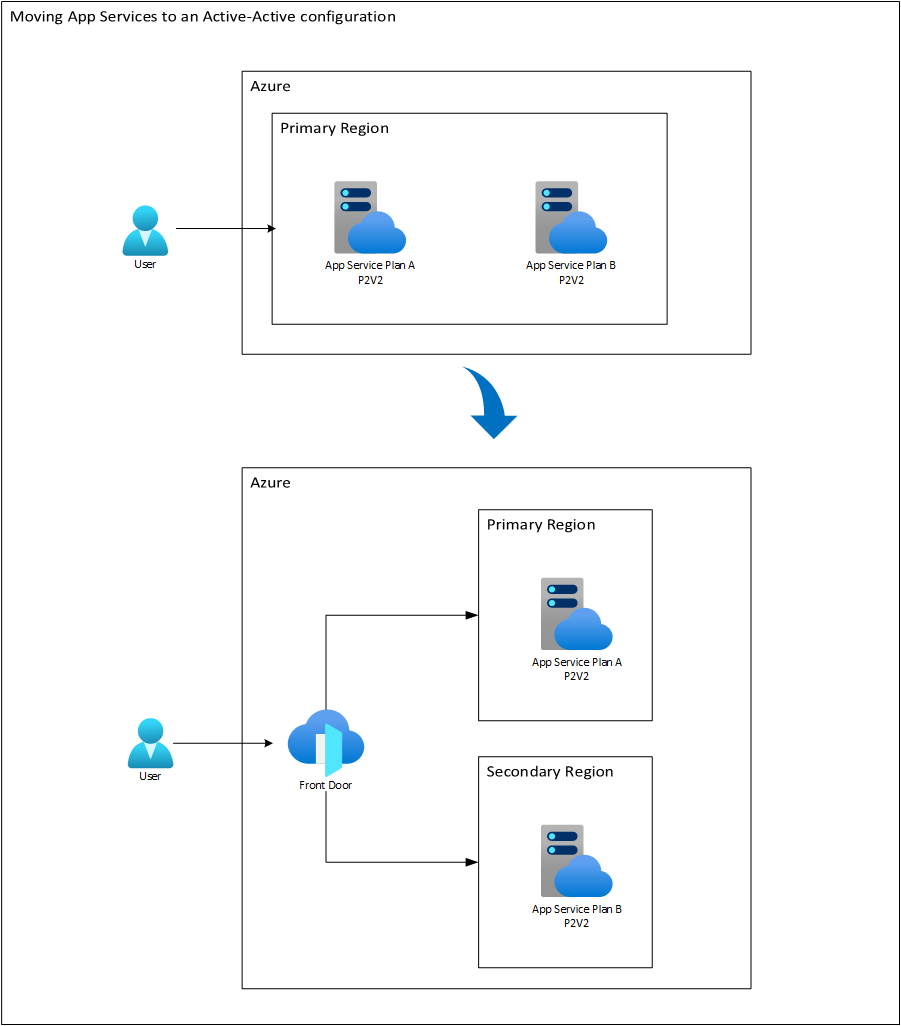
Keep in mind that although the App Service Plans are called differently, the applications they contain are the same. Only that according to the requested route, Front Door takes care of making the request to one or the other App Service Plan. In this way, each App Service Plan will end up executing different tasks. The primary will do tasks mainly of writing to the database while the secondary will take care of read-only tasks. This could mean, for example, that at a given moment we require more instances in the primary region than in the secondary. But remember that it would always be more convenient to have more predictive environments to have instances of the same size. So, as a recommendation, it is only to vary the quantity (Scale Out) instead of the size (Scale Up) for the App Service Plans in this case.
Strategy for Azure SQL Database
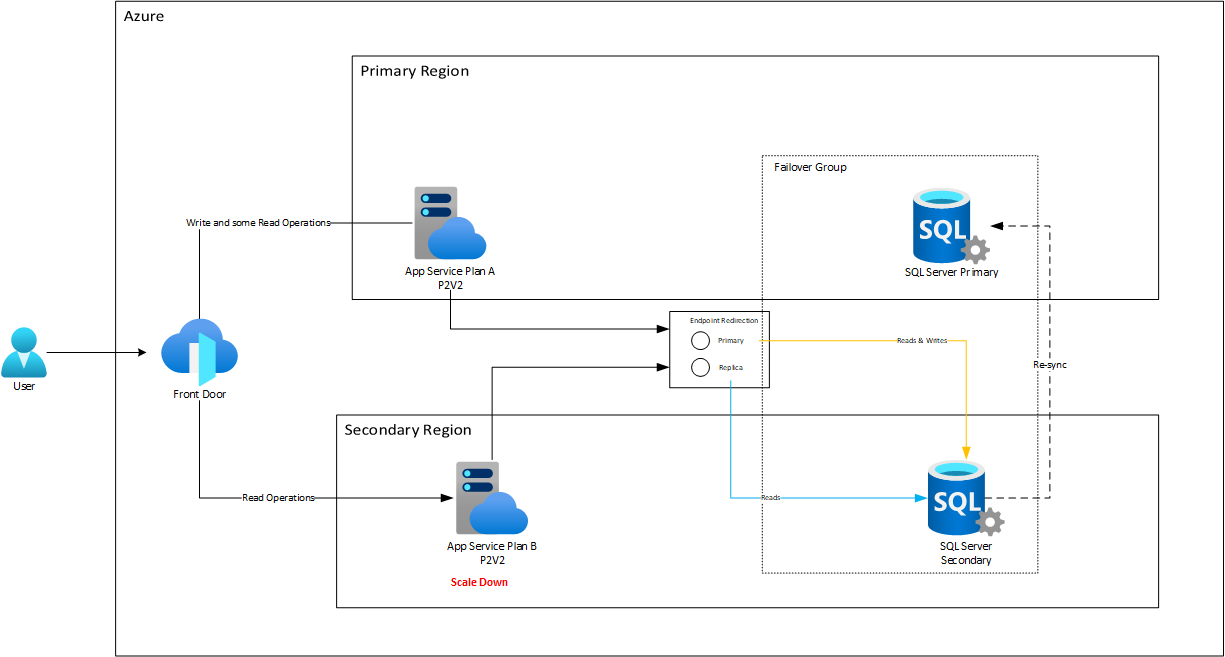
One of the most prominent features of SQL Azure in high availability management is the use of Failover Groups. These groups not only provide automatic failover and data synchronization between primary and secondary databases but also have a feature known as ‘Endpoint Redirection’.

“Endpoint Redirection” is an intrinsic advantage of Failover Groups that allows us to have a single address to which write requests are channeled (in the primary region) and another for read requests (in the secondary region). In other words, despite having multiple regions and access points, all operations that require data modification are redirected to a specific point. This cohesion ensures data integrity, avoiding potential conflicts and desynchronization.
By combining this capability with Azure Front Door, we can further enhance this feature. Front Door, thanks to its advanced traffic management capabilities, can be configured to direct all write requests to the backends deployed in the primary region of the Failover Group. In this way, each write request that enters through Front Door is not only redirected to the correct App Service (or any other backend compute service) but also, in turn, points to the designated endpoint of the Failover Group in the primary region. This creates an optimized and efficient workflow for all operations involving data changes.
On the other hand, for operations that do not involve writing, such as read queries, Azure Front Door can handle weighted load balancing. This means that a smaller portion of these requests can be directed to the primary region, while a larger proportion is sent to the secondary region. This approach not only distributes the load and minimizes latency but also leverages the available infrastructure in both regions, maximizing efficiency and availability.
Taking into account the above, along with the Active-Active architecture of App Service, we could establish a combined model with SQL Azure Database:
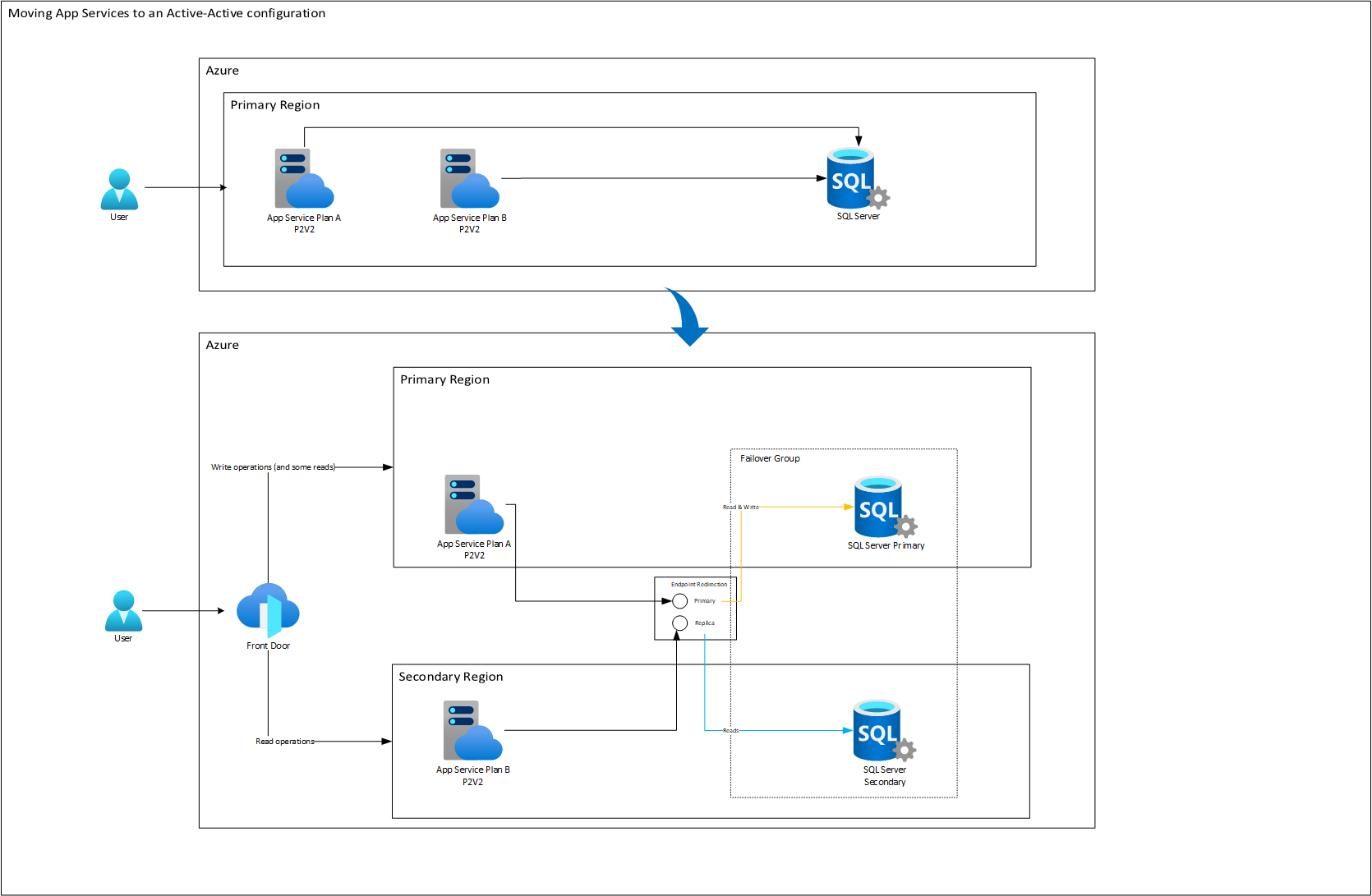
Here, the compute costs remain identical, but for SQL Database, you do need to create a replica, essentially doubling its costs. However, in the event of a disaster, the system would respond with much higher levels of RTO (Recovery Time Objective) and RPO (Recovery Point Objective) than achievable in a passive strategy. Let’s pay special attention to how the Endpoint Redirection feature automatically redirects traffic to the replica node once it’s ready after failover.
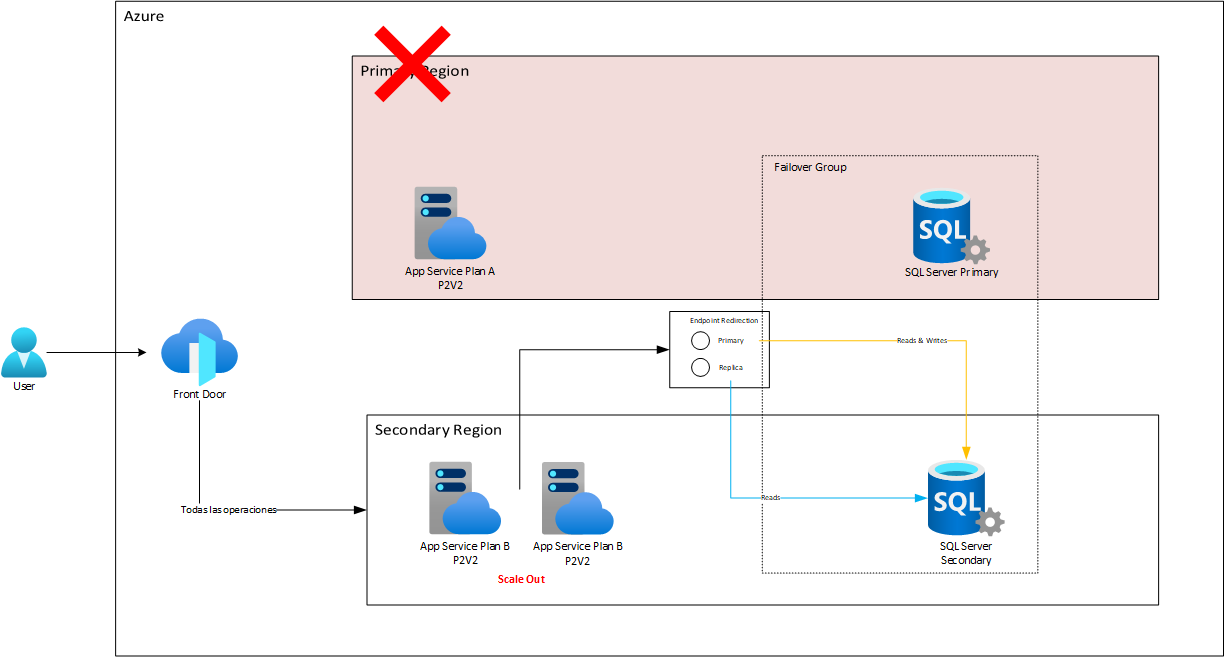
After this, during the failback, some time will pass as replication from the replica to the primary node flows to synchronize the data that was worked on during the failure. Meanwhile, the App Service will continue working with the secondary node. When the failback of Azure SQL Database is complete, then Endpoint Redirection reconfigures the traffic to its original state:
Strategy for Azure Storage
Azure Storage is essential in any cloud-based solution, offering robust and highly scalable storage. To decide on a high availability and disaster recovery strategy, it is essential to understand the differences between automatic and manual geographic replication.

Automatic Geographic Replication
Automatic replication stands out for being easy to set up, with less programming effort. It ensures that data is backed up in a secondary region, albeit asynchronously. Furthermore, it only allows writing in the primary region, which can simplify some operations and prevent concurrency conflicts.
However, this simplicity comes with its challenges. Asynchrony can result in the loss of recent data in the event of a failover. Additionally, during failover and failback events, the storage account is not available for writes, which can cause disruptions in application operations. This process also requires copying all data from the secondary region back to the primary and vice versa after recovery. Thus, the application needs to be able to operate in read-only mode during these times. Read operations in the secondary region can also be outdated due to lag in replication.
Manual Geographic Replication
The manual method provides more direct control and greater data consistency, allowing writes in any region as long as concurrency conditions are properly managed. Disruptions due to write unavailability are minimal, and you can always access up-to-date data from any region. Additionally, there’s no need to copy all the data during failback, saving time and resources.
On the other hand, the additional control comes with added complexity. It requires a custom mechanism to replicate and detect changes, which implies more development effort. There may also be additional latency in operations while changes are synchronized between both storage accounts.
In summary, depending on the specific storage-related functionalities and needs, you can opt for one strategy or the other.
Strategy for Azure Cosmos DB
Azure Cosmos DB is a unique offering within Azure’s range of database solutions. It is a database designed with an inherently distributed nature, making it ideal for high availability and disaster recovery scenarios.

Cosmos DB excels, particularly when we talk about the active-active methodology proposed for this solution. Unlike other databases, Cosmos DB allows for operations like multi-master writes, enabling simultaneous writing in multiple regions without facing conflicts. This not only increases application availability and resilience but also improves latency by allowing write operations to occur in the region closest to the user.
However, a crucial aspect to consider with Cosmos DB is its consistency model. While multi-master writes are a significant advantage, the choice of consistency level determines how data is replicated and read across different regions.
For instance, opting for a “Strong” consistency level ensures that data is up-to-date and consistent across all regions. This is an ideal choice for parts of the application that require absolute data accuracy. However, this consistency comes at a cost in terms of latency and performance.
On the other hand, there are lower consistency levels that offer reduced latency by not waiting for full data replication before completing a write or update operation. These options may be suitable for parts of the application where speed is essential and a slight delay in data propagation between regions can be tolerated. However, with lower consistency levels, there is a small risk of data loss in the event of regional failures.
Strategy for Azure Cache for Redis
The efficiency and resilience of a cloud solution are intrinsically linked to the proper management of caching. When we talk about Azure Cache for Redis, we find various geo-replication strategies that enable your application to be resilient and available in different geographic regions.

Active-Passive Replication
Azure Cache for Redis primarily offers two modes of geo-replication. The first one, called Active-Passive, available in the Premium tier, allows your Redis instance in the primary region to be automatically replicated to a secondary region. Under normal conditions, the cache can be read in the secondary region but not written to, which provides a level of scalability and relieves the primary cache from excessive read operations. However, it’s important to mention that in this secondary region, during certain synchronization processes, read errors might occur. Therefore, the code accessing it should be prepared to fall back to querying the primary region if such errors arise.
In terms of disaster recovery, this mode ensures that in the event of regional failures, the application can still access data in the secondary region while the failover is being completed.
Active-Active Replication
On the other hand, there is the Active-Active mode, which is part of the Enterprise tier. This allows active replication in up to five regions simultaneously, giving you the ability to perform both read and write operations in all of these regions. It is a more resilient and flexible option but comes with higher costs due to Redis licensing and may introduce complexities in managing potential data conflicts.
Independent Caches in Each Region
A crucial point to consider is the type of content you plan to cache. If it’s primarily static content or content that changes sporadically, you may not need to invest in geo-replication. This is because static data offers predictability; you know exactly when you need to make changes and can plan these updates for times that cause the least disruption. Moreover, by avoiding automatic replication for data that rarely changes, you reduce unnecessary costs and simplify the infrastructure by not having to deal with potential replication conflicts.
In cases like these, you can combine this approach with the active-active architecture we’ve been discussing for the backend, as there are clear benefits to managing the cache independently and persistently in each region. One of the significant advantages is reduced latency. Allowing each backend to interact with its local cache makes operations notably faster, especially beneficial for workloads with many reads. Additionally, this independence ensures that a cache failure in one region does not propagate, thus isolating potential issues. Each cache can be customized to meet the specific needs of its region, offering cost optimization and eliminating the delay introduced by replication. This is a solution very similar to the one proposed with manual geographic replication of storage, with greater ease because cached information can be reconstructed due to its ephemeral nature.
Azure Event Grid Strategy
One of the most prominent features of Azure Event Grid is its capability for automatic geo-replication. However, it’s crucial to understand that this geo-replication focuses on replicating only the service’s definition and not the data (events) themselves.

When a problem occurs in a region, and that region becomes inoperative, new events are redirected and processed by the new region that has taken control thanks to the geo-replication of the service definition. However, it’s crucial to note that the events that were already in the original region before the issue occurred will remain there, in a locked state, until the original region is restored. Once the original region becomes operational again, those events are finally dispatched.
An important consideration is the time-to-live (TTL) of these events. If the disruption in the original region extends beyond the TTL of the events, there is a real risk of these events being lost. To mitigate this risk, you can configure a “dead-letter” queue, which acts as a backup for events that couldn’t be processed in time.
If you want to have more granular control over high availability and disaster recovery, it’s recommended to implement a manual self-recovery strategy. Although this strategy offers greater control, it also requires additional client-side programming. For example, to determine which region the secondary Event Grid will operate in, you’ll need to program failover logic between two inter-regional instances of Event Grid. However, it’s essential to understand that despite this manual intervention, the challenge of handling events already sent and not yet processed still persists.
Conclusion
When designing a high availability and disaster recovery strategy for PaaS services in Azure, it’s important to consider the unique features and requirements of each application. While an active-passive strategy is commonly used, in this specific case, an active-active strategy is recommended due to the advantages it offers in terms of resilience. However, each case may have its special characteristics that warrant a different approach: if in doubt, we can communicate and collaborate to find the best solution.