Whisper + GPT. Extracting Structured Information from Recorded Conversations with Python Azure Functions, and storing results in CosmosDB
The ability to swiftly and accurately extract information from recorded conversations is a powerful asset for businesses across various sectors. Leveraging cutting-edge technologies like Azure OpenAI’s Whisper and GPT-4 models can transform raw audio into actionable insights. This blog post will walk you through a practical scenario of processing recorded conversations using Azure OpenAI services to extract valuable information than then will be stored in CosmosDB, while outlining how to adapt this process to the micro services strategy using a sample, Azure Blob Storage-triggered functions.
Scenario Description
Imagine a sales team that conducts numerous phone interviews with potential buyers to gauge their interest in your products. Each call is rich with valuable information, such as the buyer’s name, location, and specific product interests, which are crucial for tailoring future marketing and sales strategies.
Objective
Efficiently extract structured information from each recorded call to better understand the potential buyer’s preferences and needs, and then store this information in a database for easy access and analysis by the sales team.
Implementation Steps Using Azure OpenAI Whisper and GPT-4 Models:
Note: This scenario is implemented in the GitHub repo that supports this blog post.
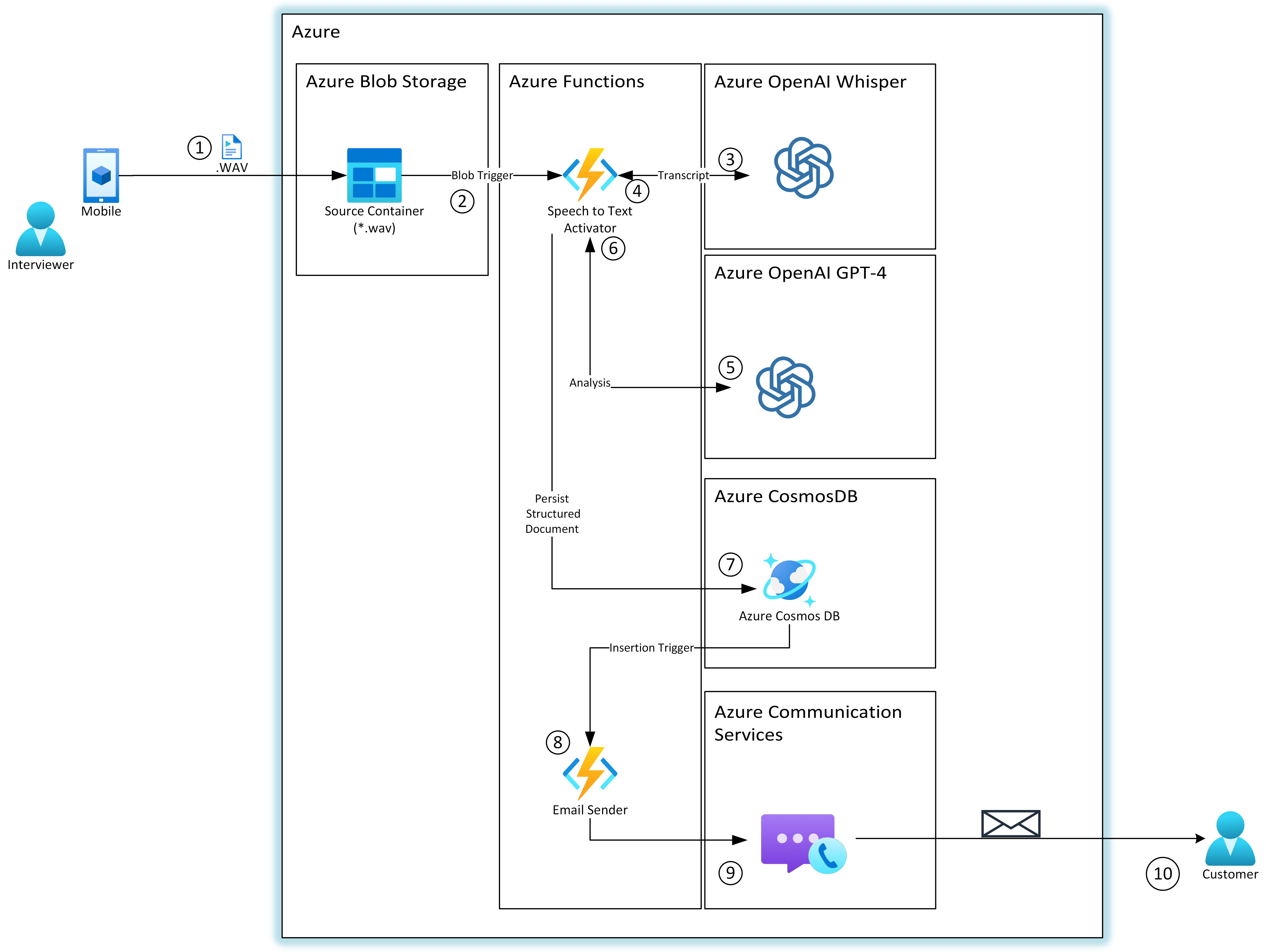
This is a high level view of the flow:
- Recording Calls:
- Sales representatives conduct interviews with potential buyers. These calls are recorded with the consent of all participants and stored as audio files in Azure Blob Storage.
- Triggering the Analysis:
- An Azure Blob Storage-triggered function is set up. Every time a new audio file (call recording) is uploaded, this function is automatically triggered.
- Processing the Audio:
- The Azure Function first reads the byte stream of the audio recording. It then uses the
NamedBytesIOclass to handle the byte stream appropriately, ensuring that it includes a file name with the necessary.wavextension for the Whisper API.
- The Azure Function first reads the byte stream of the audio recording. It then uses the
- Transcribing Audio:
- The modified byte stream is sent to the Azure OpenAI’s Whisper model, which transcribes the audio into text. This transcription converts spoken language into written text, capturing all mentioned details during the call.
- Extracting Structured Data:
- Once transcribed, the text is fed into the GPT-4 model. Using a pre-defined prompt, GPT-4 analyzes the transcription to extract structured information, such as the customer’s name, geographical location, and products of interest.
- Receiving and enrichening the structured data
- The function will add metadata to the extracted JSON to have a more useful document.
- Storing the Results:
- The extracted information, along with the transcription, is bundled into an
AnalysisResultobject. This object includes all pertinent details and metadata about the call, such as the date and time. - This structured data is then stored in Azure CosmosDB. Each entry is indexed by the call date and includes identifiers to help the sales team retrieve and analyze the data efficiently.
- The extracted information, along with the transcription, is bundled into an
- Further Processing
- Do whatever additional processing now that we have the data structured in our CosmosDB.
Architecture
This is the architecture proposed for the solution:
Handling File Metadata in Azure Blob-Triggered Functions for Compatibility with OpenAI’s Whisper Model:
When working with audio data in Python, particularly with OpenAI’s Whisper model for transcription, it’s crucial that the data not only be in a file stream format but also include metadata such as the file’s name and extension. This requirement is essential because the Whisper model uses this metadata, especially the file extension, to handle the audio data correctly based on its format (e.g., .wav, .mp3). However, when working with Azure Functions triggered by Blob storage (Azure Blob Triggered Functions), there’s a notable complication: the data returned by such triggers typically consists of a raw byte stream that lacks this necessary metadata, including the file name and extension.
To resolve this issue and ensure compatibility with the Whisper model, you can use a workaround involving the creation of a custom wrapper class that mimics a file stream complete with the required metadata attributes. For instance, the NamedBytesIO class can be defined to extend Python’s io.BytesIO class, allowing it to not only carry the byte stream but also simulate having a file name and extension. Here’s how this can be implemented:
1
2
3
4
5
6
import io
class NamedBytesIO(io.BytesIO):
def __init__(self, buffer, name):
super().__init__(buffer)
self.name = name
Once you’ve implemented the NamedBytesIO class to address the issue of missing metadata in file streams from Azure Blob Triggered Functions, the workflow to process audio data for transcription using OpenAI’s Whisper model becomes streamlined and efficient. Here’s a detailed breakdown of how the flow works after the blob trigger has been executed:
Step-by-Step Workflow Using NamedBytesIO
- Blob Trigger Activation:
- The Azure Function is triggered automatically when a new audio file is uploaded to a specified Azure Blob Storage container. The trigger is configured to pass the raw byte stream of the audio file to the function.
- Reading the Blob Content:
- Within the Azure Function, the
InputStreamobject, representing the blob, is accessed to retrieve the byte stream. Typically, this object does not include file metadata such as the file name or extension, which are crucial for the subsequent processing steps.
- Within the Azure Function, the
- Creating an Instance of NamedBytesIO:
- The raw byte stream is wrapped into an instance of the
NamedBytesIOclass. This custom class constructor takes the byte stream and the original file name (with the extension) as arguments. The file name can be extracted from the blob’s properties or explicitly provided if the storage pattern or naming conventions are predefined.1
named_stream = NamedBytesIO(blob_content, "example.wav")
- The raw byte stream is wrapped into an instance of the
- Transcription with Whisper:
- The NamedBytesIO instance, now mimicking a file-like object complete with necessary metadata, is passed to the Whisper model for transcription. Here’s how you might set up the Whisper call within the function:
1 2 3 4
transcriptionText = openAIClient.audio.transcriptions.create( file=named_stream, model="whisper-large" ).text
This step involves invoking the transcription API
- The NamedBytesIO instance, now mimicking a file-like object complete with necessary metadata, is passed to the Whisper model for transcription. Here’s how you might set up the Whisper call within the function:
Step-by-Step Process for Integrating GPT-4
- Preparing the Prompt:
- The first step involves crafting a prompt that will guide GPT-4 in analyzing the transcription. This prompt should clearly state what you expect from the model, whether it’s summarizing the content, extracting specific information, answering questions, or any other form of processing. The prompt must also include the transcription text that you obtained from the Whisper model.
1
prompt = f"Summarize the main points from the following transcript:\n\n{transcriptionText}"
- The first step involves crafting a prompt that will guide GPT-4 in analyzing the transcription. This prompt should clearly state what you expect from the model, whether it’s summarizing the content, extracting specific information, answering questions, or any other form of processing. The prompt must also include the transcription text that you obtained from the Whisper model.
- Setting Up the GPT Call:
- With the prompt ready, you can now make a call to GPT-4 using the OpenAI API. You’ll need to configure the API client with your API key and set the appropriate model parameters, including the choice of the GPT model (like
gpt-4), temperature, max tokens, and any other specific parameters that align with your goals.1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
from openai import OpenAI openai_client = OpenAI( api_key=os.getenv("AZURE_OPENAI_API_KEY"), api_version="2024-02-01", azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT") ) response = openai_client.chat.completions.create( model="gpt-4", messages=[ {"role": "system", "content": prompt} ], max_tokens=500 )
- With the prompt ready, you can now make a call to GPT-4 using the OpenAI API. You’ll need to configure the API client with your API key and set the appropriate model parameters, including the choice of the GPT model (like
Storing the Final Analysis Result Along with the Metadata in CosmosDB
When integrating AI-driven transcription and analysis into your workflows, it’s crucial to have an efficient means of storing the processed results for future reference, analytics, and operational uses. Azure CosmosDB, a globally distributed, multi-model database service, offers robust capabilities to manage JSON data at scale, making it an ideal choice for handling the outputs from such AI processes. Here, we delve into why the creation of structured objects is essential, particularly due to the requirements of CosmosDB’s data handling methods.
Necessity of Structured Objects for CosmosDB
CosmosDB primarily operates with JSON documents. To store the analysis results effectively, these results must be structured in a way that CosmosDB can process and query efficiently. In our scenario, involving the transcription and analysis data obtained from OpenAI’s Whisper and GPT models, we structure this data into two distinct objects:
TranscriptionAnalysisObject:- This object encapsulates the specific structured information extracted from the transcription, such as key data points identified by GPT-4 (e.g., customer names, dates, key topics).
- It is tailored to hold structured data that can be easily serialized into a JSON format, facilitating straightforward storage and retrieval within CosmosDB.
AnalysisResultObject:- This broader object includes not only the
TranscriptionAnalysisbut also additional metadata about the transcription process itself, such as the timestamp of the transcription, the length of the audio clip, and other pertinent metadata. - This metadata is crucial for providing context to the stored data, aiding in more comprehensive analytics and historical data tracing.
- This broader object includes not only the
CosmosDB’s Dictionary Requirement
CosmosDB requires that data to be stored is in a dictionary format (key-value pairs), which aligns with JSON document standards. To comply with this, each custom object (like TranscriptionAnalysis and AnalysisResult) must have a method to convert its attributes into a dictionary format. This is typically achieved through a method like to_dict(), which serializes the object’s properties into a dictionary:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
class TranscriptionAnalysis:
def __init__(self, customer_name, geographical_location, product_interest):
self.customer_name = customer_name
self.geographical_location = geographical_location
self.product_interest = product_interest
def to_dict(self):
return {
"customerName": self.customer_name,
"geographicalLocation": self.geographicalLocation,
"productOfInterest": self.productOfInterest
}
class AnalysisResult:
def __init__(self, date_processed, transcription, analysis, call_id):
self.date_processed = date_processed
self.transcription = transcription
self.analysis = analysis.to_dict() # Convert nested object to dict
self.call_id = call_id
def to_dict(self):
return {
"dateProcessed": self.date_processed,
"transcription": self.transcription,
"analysis": self.analysis,
"callId": self.call_id
}
Storing in CosmosDB
Once the data is structured and converted into dictionaries, it can be inserted into CosmosDB using the Cosmos DB SDK. Here’s how you might perform the insertion:
1
2
3
4
5
6
# Assume cosmos_client is initialized and configured
database = cosmos_client.get_database_client("YourDatabaseName")
container = database.get_container_client("YourContainerName")
analysis_result = AnalysisResult(...)
container.create_item(body=analysis_result.to_dict())
This structured approach to data handling not only streamlines the integration and retrieval of data for various applications but also enhances the capability of CosmosDB to serve as a dynamic and efficient database solution for handling large-scale and complex data sets. The process described here ensures that all relevant details are preserved and that data is structured in a way that is optimal for quick access and analysis, crucial for timely decision-making in business environments.
By leveraging structured data objects and CosmosDB’s powerful storage capabilities, organizations can achieve a high level of data management efficiency. This setup allows for advanced queries, data mining, and the ability to derive actionable insights from complex datasets processed through advanced AI models like OpenAI’s Whisper and GPT. Such capabilities are especially valuable in scenarios where the nuances and details captured in transcriptions can significantly influence business strategies and customer engagement outcomes.
Advantages of Using Structured Objects and CosmosDB:
- Scalability: CosmosDB’s global distribution and horizontal scaling capabilities make it ideal for applications requiring extensive data storage and fast access across multiple regions.
- Flexibility: The use of JSON-like documents for storing data allows for flexible data models and seamless changes without downtime.
- Performance: With the indexing and query capabilities of CosmosDB, retrieval and analysis of stored data become incredibly efficient, supporting real-time applications effectively.
- Integration: Structured objects can easily integrate with other Azure services, providing a cohesive environment for developers to build comprehensive solutions.
Conclusion
The integration of AI-powered transcription and analysis with Azure CosmosDB showcases the synergy between advanced computational technologies and modern database solutions. As businesses continue to embrace digital transformations, the role of structured data storage becomes increasingly critical. The methods and practices outlined in this guide not only streamline the technical processes but also pave the way for innovative applications that can harness the full potential of AI and data analytics to drive business success.