Whisper + GPT. Extracción de Información de conversaciones grabadas, con Azure Functions en Python, y almacenamiento de resultados en CosmosDB
La capacidad de extraer información de manera rápida y precisa de las conversaciones grabadas es un activo poderoso para las empresas de diversos sectores. Aprovechar tecnologías de vanguardia como los modelos Whisper y GPT-4 de Azure OpenAI puede transformar el audio crudo en conocimientos accionables. Este blog te guiará a través de un escenario práctico de procesamiento de conversaciones grabadas utilizando los servicios de Azure OpenAI para extraer información valiosa que luego será almacenada en CosmosDB, mientras describe cómo adaptar este proceso a la estrategia de microservicios utilizando un ejemplo, funciones desencadenadas por Azure Blob Storage.
Descripción del Escenario
Imagina un equipo de ventas que realiza numerosas entrevistas telefónicas con compradores potenciales para evaluar su interés en tus productos. Cada llamada está llena de información valiosa, como el nombre del comprador, ubicación e intereses específicos del producto, que son cruciales para adaptar las futuras estrategias de marketing y ventas.
Objetivo
Extraer información estructurada de cada llamada grabada para comprender mejor las preferencias y necesidades del comprador potencial, y luego almacenar esta información en una base de datos para un fácil acceso y análisis por parte del equipo de ventas.
Pasos de Implementación Usando los Modelos Azure OpenAI Whisper y GPT-4:
Nota: Este escenario está implementado en el repositorio de GitHub que soporta este blog post.
Esta es una vista de alto nivel del flujo:
- Grabación de Llamadas:
- Los representantes de ventas realizan entrevistas con compradores potenciales. Estas llamadas se graban con el consentimiento de todos los participantes y se almacenan como archivos de audio en Azure Blob Storage.
- Desencadenamiento del Análisis:
- Se configura una función desencadenada por Azure Blob Storage. Cada vez que se sube un nuevo archivo de audio (grabación de llamada), esta función se activa automáticamente.
- Procesamiento del Audio:
- La función de Azure primero lee el flujo de bytes de la grabación de audio. Luego utiliza la clase
NamedBytesIOpara manejar el flujo de bytes adecuadamente, asegurando que incluya un nombre de archivo con la extensión.wavnecesaria para la API de Whisper.
- La función de Azure primero lee el flujo de bytes de la grabación de audio. Luego utiliza la clase
- Transcripción del Audio:
- El flujo de bytes modificado se envía al modelo Whisper de Azure OpenAI, que transcribe el audio a texto. Esta transcripción convierte el lenguaje hablado en texto escrito, capturando todos los detalles mencionados durante la llamada.
- Extracción de Datos Estructurados:
- Una vez transcrita, el texto se alimenta al modelo GPT-4. Utilizando un prompt predefinido, GPT-4 analiza la transcripción para extraer información estructurada, como el nombre del cliente, ubicación geográfica y productos de interés.
- Recepción y enriquecimiento de la data estructurada
- La función añadirá metadatos al JSON extraído para tener un documento más útil.
- Almacenamiento de los Resultados:
- La información extraída, junto con la transcripción, se agrupa en un objeto
AnalysisResult. Este objeto incluye todos los detalles pertinentes y metadatos sobre la llamada, como la fecha y hora. - Estos datos estructurados se almacenan entonces en Azure CosmosDB. Cada entrada se indexa por la fecha de la llamada e incluye identificadores para ayudar al equipo de ventas a recuperar y analizar los datos de manera eficiente.
- La información extraída, junto con la transcripción, se agrupa en un objeto
- Procesamiento Adicional
- Realizar cualquier procesamiento adicional ahora que tenemos los datos estructurados en nuestro CosmosDB.
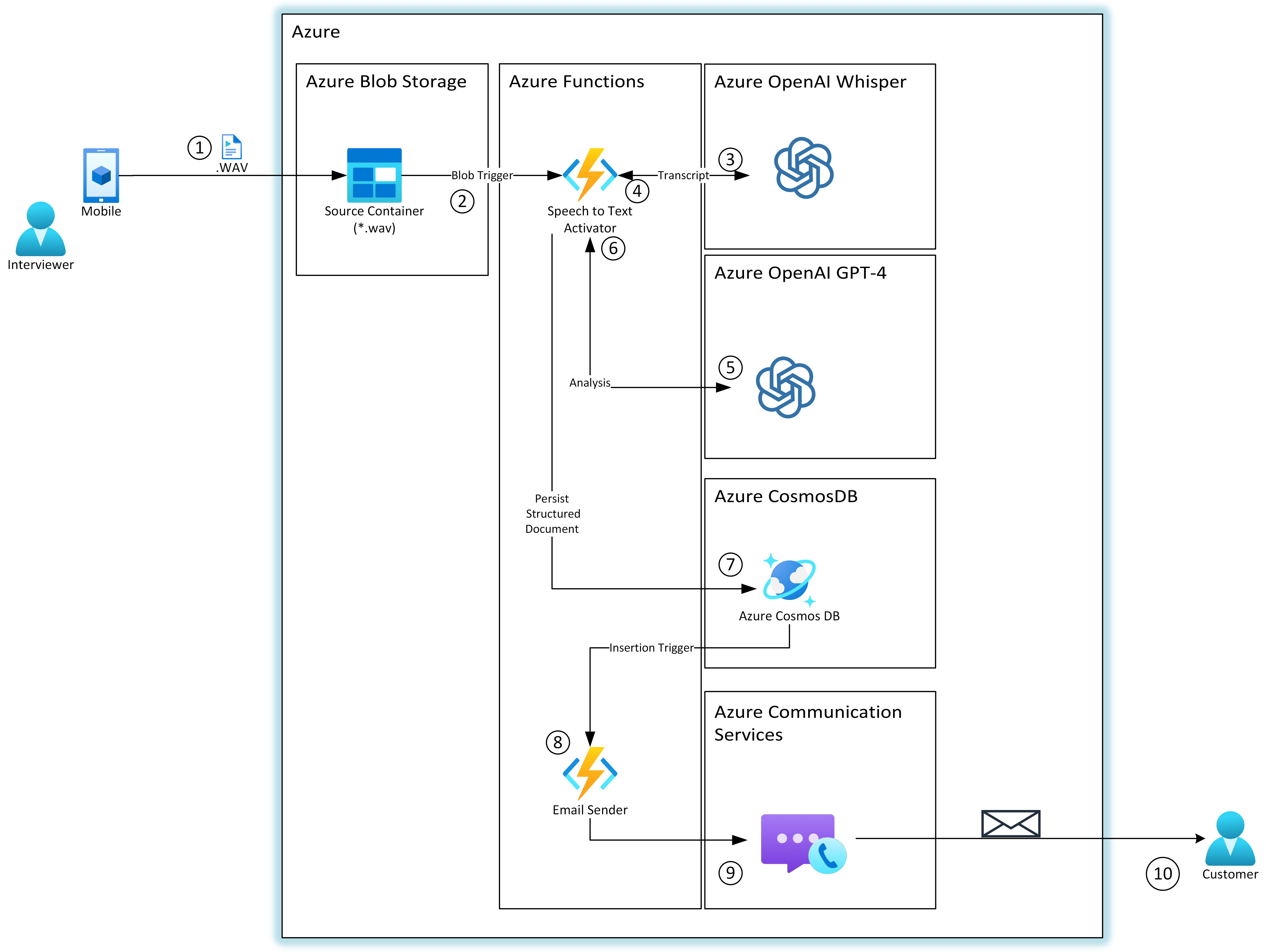
Arquitectura
Esta es la arquitectura propuesta para la solución:
Tratamiento de Metadatos de Archivos en Funciones Desencadenadas por Azure Blob para Compatibilidad con el Modelo Whisper de OpenAI:
Cuando se trabaja con datos de audio en Python, especialmente con el modelo Whisper de OpenAI para transcripción, es crucial que los datos no solo estén en formato de flujo de archivo, sino que también incluyan metadatos como el nombre y la extensión del archivo. Este requisito es esencial porque el modelo Whisper utiliza estos metadatos, especialmente la extensión del archivo, para manejar correctamente los datos de audio basados en su formato (por ejemplo, .wav, .mp3). Sin embargo, al trabajar con funciones de Azure desencadenadas por almacenamiento Blob (funciones desencadenadas por Azure Blob), hay una complicación notable: los datos devueltos por dichos desencadenadores típicamente consisten en un flujo de bytes crudo que carece de estos metadatos necesarios, incluyendo el nombre y la extensión del archivo.
Para resolver este problema y asegurar la compatibilidad con el modelo Whisper, puedes usar una solución que involucra la creación de una clase de envoltura personalizada que imita un flujo de archivo completo con los atributos de metadatos requeridos. Por ejemplo, la clase NamedBytesIO puede definirse para extender la clase io.BytesIO de Python, permitiéndole no solo llevar el flujo de bytes sino también simular tener un nombre de archivo y extensión. Así es como se puede implementar:
1
2
3
4
5
6
import io
class NamedBytesIO(io.BytesIO):
def __init__(self, buffer, name):
super().__init__(buffer)
self.name = name
Una vez que hayas implementado la clase NamedBytesIO para abordar el problema de la falta de metadatos en los flujos de bytes de las Funciones Desencadenadas por Azure Blob, el flujo de trabajo para procesar datos de audio para transcripción usando el modelo Whisper de OpenAI se vuelve ágil y eficiente. Aquí tienes un desglose detallado de cómo funciona el flujo después de que se ejecuta el desencadenador de blob:
Flujo de Trabajo Paso a Paso Usando NamedBytesIO
Activación del Desencadenador de Blob:
- La función de Azure se activa automáticamente cuando se sube un nuevo archivo de audio a un contenedor de Azure Blob Storage especificado. El desencadenador está configurado para pasar el flujo de bytes crudo del archivo de audio a la función.
Lectura del Contenido del Blob:
- Dentro de la función de Azure, el objeto
InputStream, que representa el blob, se accede para recuperar el flujo de bytes. Típicamente, este objeto no incluye metadatos de archivo como el nombre o la extensión, que son cruciales para los pasos de procesamiento subsiguientes.
- Dentro de la función de Azure, el objeto
Creación de una Instancia de NamedBytesIO:
- El flujo de bytes crudo se envuelve en una instancia de la clase
NamedBytesIO. Este constructor de clase personalizado toma el flujo de bytes y el nombre de archivo original (con la extensión) como argumentos. El nombre del archivo puede extraerse de las propiedades del blob o proporcionarse explícitamente si el patrón de almacenamiento o las convenciones de nomenclatura están predefinidas.
1
named_stream = NamedBytesIO(blob_content, "example.wav")
- El flujo de bytes crudo se envuelve en una instancia de la clase
Transcripción con Whisper:
- La instancia de NamedBytesIO, ahora imitando un objeto de archivo completo con metadatos necesarios, se pasa al modelo Whisper para la transcripción. Así es como podrías configurar la llamada de Whisper dentro de la función:
1 2 3 4
transcriptionText = openAIClient.audio.transcriptions.create( file=named_stream, model="whisper-large" ).text
Este paso implica invocar la API de transcripción
Proceso Paso a Paso para Integrar GPT-4
- Preparación del Prompt:
- El primer paso implica elaborar un prompt que guiará a GPT-4 en el análisis de la transcripción. Este prompt debe indicar claramente lo que esperas del modelo, ya sea resumir el contenido, extraer información específica, responder preguntas u otra forma de procesamiento. El prompt también debe incluir el texto de la transcripción que obtuviste del modelo Whisper.
1
prompt = f"Resumir los puntos principales de la siguiente transcripción:\n\n{transcriptionText}"
Configuración de la Llamada GPT:
- Con el prompt listo, ahora puedes hacer una llamada a GPT-4 usando la API de OpenAI. Necesitarás configurar el cliente de la API con tu clave de API y establecer los parámetros del modelo apropiados, incluyendo la elección del modelo GPT (como
gpt-4), temperatura, máximos tokens y cualquier otro parámetro específico que se alinee con tus objetivos.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
from openai import OpenAI openai_client = OpenAI( api_key=os.getenv("AZURE_OPENAI_API_KEY"), api_version="2024-02-01", azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT") ) response = openai_client.chat.completions.create( model="gpt-4", messages=[ {"role": "system", "content": prompt} ], max_tokens=500 )
- Con el prompt listo, ahora puedes hacer una llamada a GPT-4 usando la API de OpenAI. Necesitarás configurar el cliente de la API con tu clave de API y establecer los parámetros del modelo apropiados, incluyendo la elección del modelo GPT (como
Almacenamiento del Resultado Final del Análisis Junto con los Metadatos en CosmosDB
Cuando integras la transcripción y el análisis impulsados por IA en tus flujos de trabajo, es crucial tener un medio eficiente de almacenar los resultados procesados para futuras referencias, análisis y usos operativos. Azure CosmosDB, un servicio de base de datos multimodelo distribuido globalmente, ofrece capacidades robustas para manejar datos JSON a gran escala, lo que lo hace una opción ideal para manejar las salidas de tales procesos de IA. Aquí, profundizamos en por qué la creación de objetos estructurados es esencial, particularmente debido a los requisitos de los métodos de manejo de datos de CosmosDB.
Necesidad de Objetos Estructurados para CosmosDB
CosmosDB opera principalmente con documentos JSON. Para almacenar los resultados del análisis de manera efectiva, estos resultados deben estar estructurados de manera que CosmosDB pueda procesarlos y consultarlos eficientemente. En nuestro escenario, que involucra los datos de transcripción y análisis obtenidos de los modelos Whisper y GPT de OpenAI, estructuramos estos datos en dos objetos distintos:
- Objeto
TranscriptionAnalysis:- Este objeto encapsula la información estructurada específica extraída de la transcripción, como los puntos clave identificados por GPT-4 (por ejemplo, nombres de clientes, fechas, temas clave).
- Está diseñado para contener datos estructurados que pueden ser fácilmente serializados en un formato JSON, facilitando el almacenamiento y la recuperación directos dentro de CosmosDB.
- Objeto
AnalysisResult:- Este objeto más amplio incluye no solo el
TranscriptionAnalysissino también metadatos adicionales sobre el proceso de transcripción en sí, como la marca de tiempo de la transcripción, la longitud del clip de audio y otros metadatos pertinentes. - Estos metadatos son cruciales para proporcionar contexto a los datos almacenados, ayudando en análisis más comprensivos y rastreo de datos históricos.
- Este objeto más amplio incluye no solo el
Requerimiento de Diccionario de CosmosDB
CosmosDB requiere que los datos que se almacenarán estén en un formato de diccionario (pares clave-valor), que se alinea con los estándares de documentos JSON. Para cumplir con esto, cada objeto personalizado (como TranscriptionAnalysis y AnalysisResult) debe tener un método para convertir sus atributos en un formato de diccionario. Esto se logra típicamente a través de un método como to_dict(), que serializa las propiedades del objeto en un diccionario:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
class TranscriptionAnalysis:
def __init__(self, customer_name, geographical_location, product_interest):
self.customer_name = customer_name
self.geographical_location = geographical_location
self.product_interest = product_interest
def to_dict(self):
return {
"customerName": self.customer_name,
"geographicalLocation": self.geographicalLocation,
"productInterest": this.product_interest
}
class AnalysisResult:
def __init__(self, date_processed, transcription, analysis, call_id):
this.date_processed = date_processed
this.transcription = transcription
this.analysis = analysis.to_dict() # Convertir objeto anidado a dict
this.call_id = call_id
def to_dict(self):
return {
"dateProcessed": this.date_processed,
"transcription": this.transcription,
"analysis": this.analysis,
"callId": this.call_id
}
Almacenando en CosmosDB
Una vez que los datos están estructurados y convertidos en diccionarios, se pueden insertar en CosmosDB usando el SDK de Cosmos DB. Así es como podrías realizar la inserción:
1
2
3
4
5
6
# Suponiendo que cosmos_client está inicializado y configurado
database = cosmos_client.get_database_client("TuNombreDeBaseDeDatos")
container = database.get_container_client("TuNombreDeContenedor")
analysis_result = AnalysisResult(...)
container.create_item(body=analysis_result.to_dict())
Este enfoque estructurado para el manejo de datos no solo agiliza la integración y recuperación de datos para varias aplicaciones, sino que también mejora la capacidad de CosmosDB para servir como una solución de base de datos dinámica y eficiente para manejar conjuntos de datos grandes y complejos. El proceso descrito aquí asegura que todos los detalles relevantes se conservan y que los datos están estructurados de manera óptima para un acceso y análisis rápidos, crucial para la toma de decisiones oportuna en entornos empresariales.
Al aprovechar los objetos de datos estructurados y las poderosas capacidades de almacenamiento de CosmosDB, las organizaciones pueden alcanzar un alto nivel de eficiencia en la gestión de datos. Este configuración permite consultas avanzadas, minería de datos y la capacidad de derivar conocimientos accionables de conjuntos de datos complejos procesados a través de modelos de IA avanzados como los modelos Whisper y GPT de OpenAI. Tales capacidades son especialmente valiosas en escenarios donde los matices y detalles capturados en las transcripciones pueden influir significativamente en las estrategias empresariales y los resultados de compromiso con los clientes.
Ventajas de Usar Objetos Estructurados y CosmosDB:
- Escalabilidad: Las capacidades de distribución global y escalado horizontal de CosmosDB lo hacen ideal para aplicaciones que requieren almacenamiento de datos extenso y acceso rápido en múltiples regiones.
- Flexibilidad: El uso de documentos similares a JSON para almacenar datos permite modelos de datos flexibles y cambios sin interrupciones.
- Rendimiento: Con las capacidades de indexación y consulta de CosmosDB, la recuperación y análisis de datos almacenados se vuelven increíblemente eficientes, apoyando efectivamente las aplicaciones en tiempo real.
- Integración: Los objetos estructurados pueden integrarse fácilmente con otros servicios de Azure, proporcionando un entorno cohesivo para que los desarrolladores construyan soluciones integrales.
Conclusión
La integración de la transcripción y análisis impulsados por IA con Azure CosmosDB muestra la sinergia entre las tecnologías computacionales avanzadas y las soluciones modernas de bases de datos. A medida que las empresas continúan adoptando transformaciones digitales, el papel del almacenamiento de datos estructurados se vuelve cada vez más crítico. Los métodos y prácticas descritos en esta guía no solo agilizan los procesos técnicos sino que también allanan el camino para aplicaciones innovadoras que pueden aprovechar todo el potencial de la IA y el análisis de datos para impulsar el éxito empresarial.