Whisper + GPT. Extração de Informações Estruturadas de Conversas Gravadas com Python Azure Functions, e armazenando resultados no CosmosDB
A capacidade de extrair informações de forma rápida e precisa de conversas gravadas é um ativo poderoso para empresas de vários setores. Utilizar tecnologias de ponta como os modelos Whisper e GPT-4 da Azure OpenAI pode transformar áudio bruto em insights acionáveis. Este post do blog irá guiá-lo através de um cenário prático de processamento de conversas gravadas usando os serviços Azure OpenAI para extrair informações valiosas que serão armazenadas no CosmosDB, delineando como adaptar esse processo para a estratégia de micro serviços usando um exemplo, funções acionadas por armazenamento Azure Blob.
Descrição do Cenário
Imagine uma equipe de vendas que realiza inúmeras entrevistas telefônicas com potenciais compradores para avaliar o interesse deles em seus produtos. Cada chamada é rica em informações valiosas, como o nome do comprador, localização e interesses específicos do produto, que são cruciais para adaptar futuras estratégias de marketing e vendas.
Objetivo
Extrair de forma eficiente informações estruturadas de cada chamada gravada para entender melhor as preferências e necessidades do comprador potencial, e então armazenar essas informações em um banco de dados para fácil acesso e análise pela equipe de vendas.
Etapas de Implementação Usando Azure OpenAI Whisper e Modelos GPT-4:
Nota: Este cenário é implementado no repositório GitHub que suporta este post do blog.
Esta é uma visão de alto nível do fluxo:
- Gravação de Chamadas:
- Representantes de vendas conduzem entrevistas com potenciais compradores. Essas chamadas são gravadas com o consentimento de todos os participantes e armazenadas como arquivos de áudio no Azure Blob Storage.
- Disparo da Análise:
- Uma função acionada pelo Azure Blob Storage é configurada. Toda vez que um novo arquivo de áudio (gravação de chamada) é carregado, essa função é automaticamente disparada.
- Processamento do Áudio:
- A função Azure primeiro lê o fluxo de bytes da gravação de áudio. Em seguida, usa a classe
NamedBytesIOpara manipular o fluxo de bytes adequadamente, garantindo que ele inclua um nome de arquivo com a extensão.wavnecessária para a API Whisper.
- A função Azure primeiro lê o fluxo de bytes da gravação de áudio. Em seguida, usa a classe
- Transcrição do Áudio:
- O fluxo de bytes modificado é enviado para o modelo Whisper da Azure OpenAI, que transcreve o áudio em texto. Esta transcrição converte a linguagem falada em texto escrito, capturando todos os detalhes mencionados durante a chamada.
- Extração de Dados Estruturados:
- Uma vez transcrita, o texto é alimentado no modelo GPT-4. Usando um prompt pré-definido, o GPT-4 analisa a transcrição para extrair informações estruturadas, como o nome do cliente, localização geográfica e produtos de interesse.
- Recebimento e Enriquecimento dos Dados Estruturados
- A função adicionará metadados ao JSON extraído para ter um documento mais útil.
- Armazenamento dos Resultados:
- As informações extraídas, juntamente com a transcrição, são agrupadas em um objeto
AnalysisResult. Este objeto inclui todos os detalhes pertinentes e metadados sobre a chamada, como a data e hora. - Esses dados estruturados são então armazenados no Azure CosmosDB. Cada entrada é indexada pela data da chamada e inclui identificadores para ajudar a equipe de vendas a recuperar e analisar os dados de forma eficiente.
- As informações extraídas, juntamente com a transcrição, são agrupadas em um objeto
- Processamento Adicional
- Faça qualquer processamento adicional agora que temos os dados estruturados em nosso CosmosDB.\
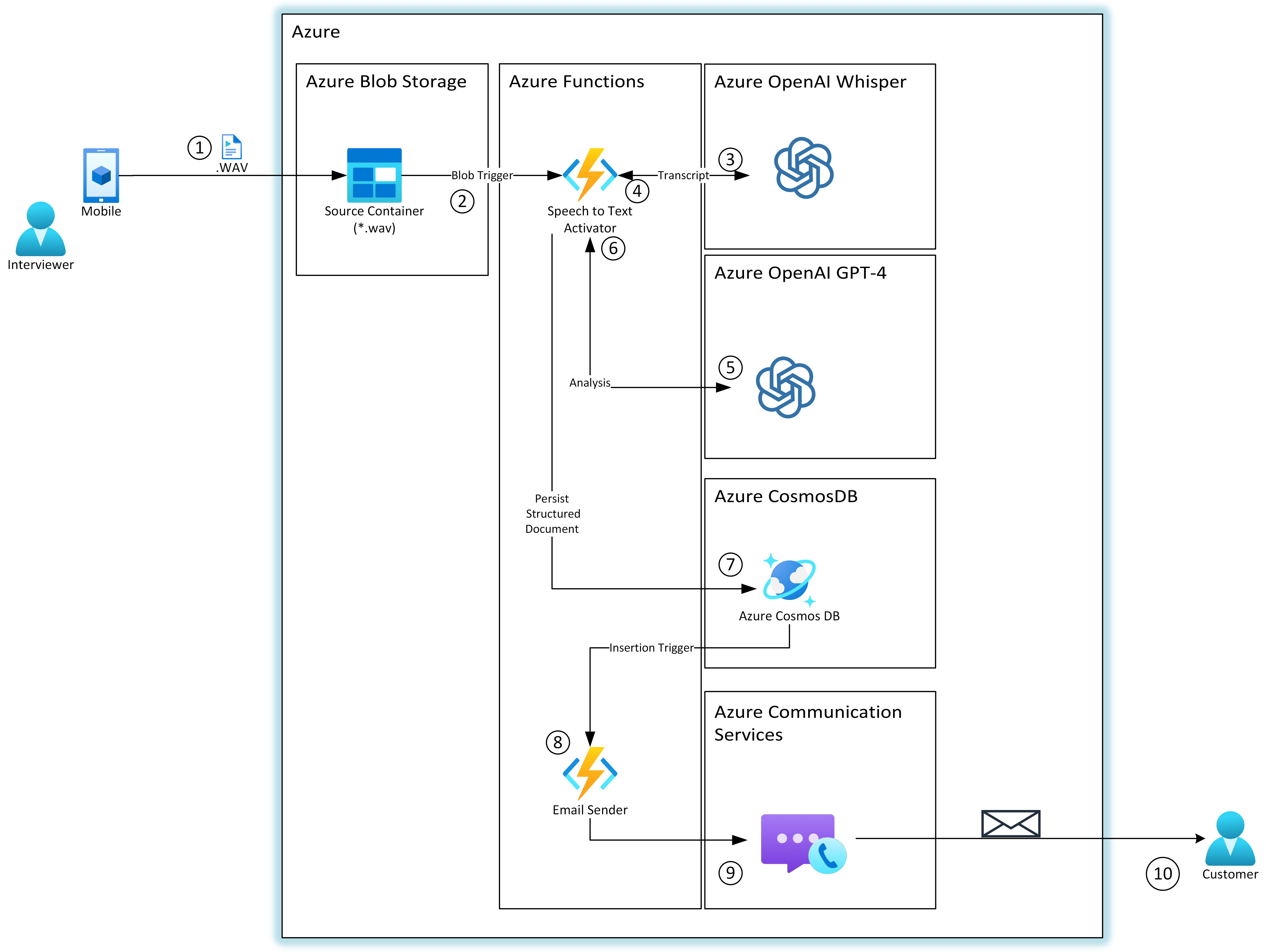
Arquitetura
Esta é a arquitetura proposta para a solução:
Manipulação de Metadados de Arquivo em Funções do Azure Blob-Triggered para Compatibilidade com o Modelo Whisper da OpenAI:
Ao trabalhar com dados de áudio em Python, especialmente com o modelo de transcrição Whisper da OpenAI, é crucial que os dados não estejam apenas em formato de fluxo de arquivo, mas também incluam metadados, como o nome e a extensão do arquivo. Este requisito é essencial porque o modelo Whisper usa esses metadados, especialmente a extensão do arquivo, para manipular corretamente os dados de áudio com base em seu formato (por exemplo, .wav, .mp3). No entanto, ao trabalhar com Azure Functions acionadas por armazenamento Blob (Azure Blob Triggered Functions), há uma complicação notável: os dados retornados por esses gatilhos geralmente consistem em um fluxo de bytes puro que não possui os metadados necessários, incluindo o nome e a extensão do arquivo.
Para resolver essa questão e garantir a compatibilidade com o modelo Whisper, você pode usar uma solução envolvendo a criação de uma classe de encapsulamento personalizada que imita um fluxo de arquivo completo com os atributos de metadados necessários. Por exemplo, a classe NamedBytesIO pode ser definida para estender a classe io.BytesIO do Python, permitindo que ela não apenas carregue o fluxo de bytes, mas também simule ter um nome e extensão de arquivo. Veja como isso pode ser implementado:
1
2
3
4
5
6
import io
class NamedBytesIO(io.BytesIO):
def __init__(self, buffer, name):
super().__init__(buffer)
self.name = name
Uma vez que você tenha implementado a classe NamedBytesIO para abordar a questão dos metadados ausentes em fluxos de arquivo de Azure Blob Triggered Functions, o fluxo de trabalho para processar dados de áudio para transcrição usando o modelo Whisper da OpenAI torna-se simplificado e eficiente. Aqui está uma descrição detalhada de como o fluxo funciona após o gatilho de blob ser executado:
Fluxo de Trabalho Passo a Passo Usando NamedBytesIO
Ativação do Gatilho de Blob:
- A função Azure é acionada automaticamente quando um novo arquivo de áudio é carregado em um contêiner especificado do Azure Blob Storage. O gatilho é configurado para passar o fluxo de bytes puro do arquivo de áudio para a função.
Leitura do Conteúdo do Blob:
- Dentro da função Azure, o objeto
InputStream, representando o blob, é acessado para recuperar o fluxo de bytes. Normalmente, este objeto não inclui metadados do arquivo, como o nome ou a extensão, que são cruciais para as etapas de processamento subsequentes.
- Dentro da função Azure, o objeto
Criação de uma Instância de NamedBytesIO:
- O fluxo de bytes puro é envolto em uma instância da classe
NamedBytesIO. Este construtor de classe personalizado toma o fluxo de bytes e o nome original do arquivo (com a extensão) como argumentos. O nome do arquivo pode ser extraído das propriedades do blob ou fornecido explicitamente se o padrão de armazenamento ou convenções de nomenclatura forem predefinidos.
1 2
pythonCopy code named_stream = NamedBytesIO(blob_content, "example.wav")
- O fluxo de bytes puro é envolto em uma instância da classe
Transcrição com Whisper:
- A instância de NamedBytesIO, agora imitando um objeto de arquivo completo com metadados necessários, é passada para o modelo Whisper para transcrição. Veja como você pode configurar a chamada Whisper dentro da função:
1 2 3 4
pythonCopy code transcriptionText = openAIClient.audio.transcriptions.create( file=named_stream, model="whisper-large" ).textEsta etapa envolve invocar a API de transcrição
Processo Passo a Passo para Integração do GPT-4
Preparando o Prompt:
- O primeiro passo envolve elaborar um prompt que guiará o GPT-4 na análise da transcrição. Este prompt deve declarar claramente o que você espera do modelo, seja resumindo o conteúdo, extraindo informações específicas, respondendo perguntas ou qualquer outra forma de processamento. O prompt também deve incluir o texto da transcrição que você obteve do modelo Whisper.
1
prompt = f"Resuma os principais pontos da seguinte transcrição:\n\n{transcriptionText}"
Configuração da Chamada GPT:
- Com o prompt pronto, agora você pode fazer uma chamada ao GPT-4 usando a API OpenAI. Você precisará configurar o cliente da API com sua chave API e definir os parâmetros do modelo apropriados, incluindo a escolha do modelo GPT (como
gpt-4), temperatura, max tokens e quaisquer outros parâmetros específicos que estejam alinhados com seus objetivos.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
from openai import OpenAI openai_client = OpenAI( api_key=os.getenv("AZURE_OPENAI_API_KEY"), api_version="2024-02-01", azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT") ) response = openai_client.chat.completions.create( model="gpt-4", messages=[ {"role": "system", "content": prompt} ], max_tokens=500 )
- Com o prompt pronto, agora você pode fazer uma chamada ao GPT-4 usando a API OpenAI. Você precisará configurar o cliente da API com sua chave API e definir os parâmetros do modelo apropriados, incluindo a escolha do modelo GPT (como
Armazenando o Resultado Final da Análise Junto com os Metadados no CosmosDB
Quando você integra a transcrição e análise impulsionadas por IA em seus fluxos de trabalho, é crucial ter um meio eficiente de armazenar os resultados processados para referência futura, análises e usos operacionais. O Azure CosmosDB, um serviço de banco de dados multimodelo e distribuído globalmente, oferece capacidades robustas para gerenciar dados JSON em larga escala, tornando-o uma escolha ideal para lidar com as saídas desses processos de IA. Aqui, exploramos por que a criação de objetos estruturados é essencial, particularmente devido aos requisitos dos métodos de manipulação de dados do CosmosDB.
Necessidade de Objetos Estruturados para o CosmosDB
O CosmosDB opera principalmente com documentos JSON. Para armazenar os resultados da análise de forma eficaz, esses resultados devem ser estruturados de uma maneira que o CosmosDB possa processar e consultar eficientemente. Em nosso cenário, envolvendo os dados de transcrição e análise obtidos dos modelos Whisper e GPT da OpenAI, estruturamos esses dados em dois objetos distintos:
- Objeto
TranscriptionAnalysis:- Este objeto encapsula as informações estruturadas específicas extraídas da transcrição, como os pontos de dados chave identificados pelo GPT-4 (por exemplo, nomes de clientes, datas, tópicos principais).
- Ele é feito para conter dados estruturados que podem ser facilmente serializados em um formato JSON, facilitando o armazenamento e a recuperação diretos dentro do CosmosDB.
- Objeto
AnalysisResult:- Este objeto mais amplo inclui não apenas a
TranscriptionAnalysis, mas também metadados adicionais sobre o próprio processo de transcrição, como o carimbo de data/hora da transcrição, o comprimento do clipe de áudio e outros metadados pertinentes. - Esses metadados são cruciais para fornecer contexto aos dados armazenados, auxiliando em análises mais abrangentes e rastreamento de dados históricos.
- Este objeto mais amplo inclui não apenas a
Requisito de Dicionário do CosmosDB
O CosmosDB exige que os dados a serem armazenados estejam em um formato de dicionário (pares chave-valor), que esteja alinhado com os padrões de documentos JSON. Para cumprir isso, cada objeto personalizado (como TranscriptionAnalysis e AnalysisResult) deve ter um método para converter seus atributos em um formato de dicionário. Isso é geralmente alcançado através de um método como to_dict(), que serializa as propriedades do objeto em um dicionário:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
class TranscriptionAnalysis:
def __init__(self, customer_name, geographical_location, product_interest):
self.customer_name = customer_name
self.geographical_location = geographical_location
self.product_interest = product_interest
def to_dict(self):
return {
"customerName": self.customer_name,
"geographicalLocation": self.geographicalLocation,
"productOfInterest": self.productOfInterest
}
class AnalysisResult:
def __init__(self, date_processed, transcription, analysis, call_id):
self.date_processed = date_processed
self.transcription = transcription
self.analysis = analysis.to_dict() # Converter objeto aninhado em dict
self.call_id = call_id
def to_dict(self):
return {
"dateProcessed": self.date_processed,
"transcription": self.transcription,
"analysis": self.analysis,
"callId": self.call_id
}
Armazenando no CosmosDB
Uma vez que os dados estejam estruturados e convertidos em dicionários, eles podem ser inseridos no CosmosDB usando o SDK do Cosmos DB. Veja como você poderia realizar a inserção:
1
2
3
4
5
6
# Assuma que cosmos_client está inicializado e configurado
database = cosmos_client.get_database_client("YourDatabaseName")
container = database.get_container_client("YourContainerName")
analysis_result = AnalysisResult(...)
container.create_item(body=analysis_result.to_dict())
Essa abordagem estruturada para o manuseio de dados não apenas simplifica a integração e a recuperação de dados para várias aplicações, mas também aprimora a capacidade do CosmosDB de servir como uma solução de banco de dados dinâmica e eficiente para lidar com conjuntos de dados grandes e complexos. O processo descrito aqui garante que todos os detalhes relevantes sejam preservados e que os dados sejam estruturados de uma maneira que seja ótima para acesso e análise rápidos, crucial para a tomada de decisões em tempo hábil em ambientes empresariais.
Ao aproveitar objetos de dados estruturados e as poderosas capacidades de armazenamento do CosmosDB, as organizações podem alcançar um alto nível de eficiência na gestão de dados. Essa configuração permite consultas avançadas, mineração de dados e a capacidade de obter insights acionáveis de conjuntos de dados complexos processados através de modelos avançados de IA como o Whisper da OpenAI e o GPT. Essas capacidades são especialmente valiosas em cenários onde as nuances e detalhes capturados nas transcrições podem influenciar significativamente as estratégias empresariais e os resultados do envolvimento com o cliente.
Vantagens de Usar Objetos Estruturados e o CosmosDB:
- Escalabilidade: A distribuição global e as capacidades de escalonamento horizontal do CosmosDB o tornam ideal para aplicações que requerem armazenamento de dados extensivo e acesso rápido em múltiplas regiões.
- Flexibilidade: O uso de documentos semelhantes a JSON para armazenar dados permite modelos de dados flexíveis e mudanças contínuas sem tempo de inatividade.
- Desempenho: Com as capacidades de indexação e consulta do CosmosDB, a recuperação e análise de dados armazenados tornam-se incrivelmente eficientes, apoiando efetivamente aplicações em tempo real.
- Integração: Objetos estruturados podem ser facilmente integrados com outros serviços Azure, proporcionando um ambiente coeso para desenvolvedores construírem soluções abrangentes.
Conclusão
A integração da transcrição e análise alimentadas por IA com o Azure CosmosDB demonstra a sinergia entre tecnologias computacionais avançadas e soluções modernas de banco de dados. À medida que as empresas continuam a abraçar transformações digitais, o papel do armazenamento de dados estruturados torna-se cada vez mais crítico. Os métodos e práticas delineados neste guia não apenas simplificam os processos técnicos, mas também pavimentam o caminho para aplicações inovadoras que podem aproveitar todo o potencial da IA e da análise de dados para impulsionar o sucesso empresarial.